巅峰对决!谷歌Gemini嵌入模型击败OpenAI,问鼎MTEB全球第一
文章来源:智汇AI 发布时间:2025-07-15
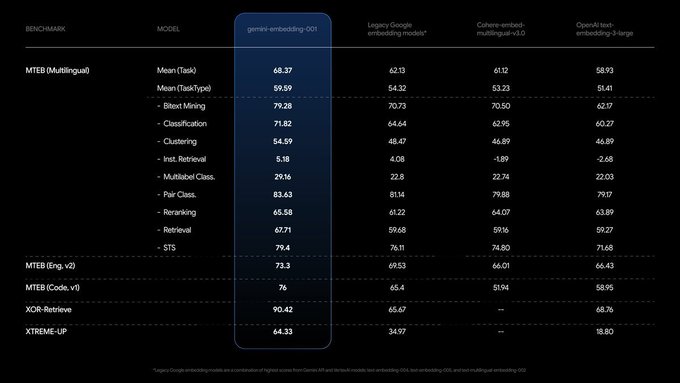
2025年7月15日,谷歌深夜抛出重磅炸弹——Gemini嵌入模型以68.37分登顶MTEB榜单,碾压OpenAI的58.93分!这款模型不仅技术全面,多语言能力突出,更以每100万token仅0.…
暂无访问2025年7月15日凌晨1点,谷歌悄悄放了个大招——首个Gemini嵌入模型正式发布,直接在多文本嵌入基准测试平台(MTEB)上以68.37分登顶,把OpenAI的58.93分远远甩在身后。这一成绩不仅让谷歌在嵌入技术领域稳坐头把交椅,更给独立创作者和自由职业者送来了一份“经济实惠”的大礼:每100万token仅需0.15美元,成本直接拉低,性价比拉满!
Gemini嵌入模型是什么?
Gemini嵌入模型是谷歌推出的创新性文本嵌入模型。它基于Gemini模型训练,能将文本转化为高维度数值向量以捕捉语义和上下文信息。该模型支持超过100种语言,输入标记长度可达8K,输出为3K维向量,并可通过MRL技术灵活调整维度以优化存储成本。它适用于信息检索、文本分类等多种场景,已集成至GeminiAPI,且在多文本嵌入基准测试平台(MTEB)上表现优异,以高分登顶,展现出强大的文本处理能力。
Gemini嵌入模型官网地址
体验地址:GoogleAIStudio:谷歌在线平台(该模型在谷歌在线平台上体验)
Gemini嵌入模型:为啥这么强?1.多任务全能选手,双语能力更亮眼
Gemini嵌入模型可不是“偏科生”。根据测试结果,它在双语挖掘、分类、聚类、指令检索、多标签分类、配对分类、重排、检索和语义文本相似性等任务中表现堪称“全能王”。尤其是它的多语言能力,让它在全球范围内的应用潜力大增——毕竟,英语母语者只是全球用户的一部分,非英语用户的需求同样不容忽视。
2.架构创新:双向Transformer+池化层,简单有效
Gemini嵌入模型基于双向Transformer编码器架构设计,保留了Gemini模型的双向注意力机制,这让它在语言理解上更上一层楼。更值得一提的是,模型在底层32层Transformer的基础上,加了一个池化层,通过均值池化策略将输入序列的每个token嵌入聚合,生成单一的嵌入向量。这种设计简单却高效,大大增强了模型的适应性。
训练方法:分阶段精调,数据质量是关键1.预微调+精调:从大规模语料到任务特化
Gemini嵌入模型的训练策略分为两步走:
预微调阶段:用大规模Web语料库训练,目标是让模型从“自回归生成任务”过渡到“编码任务”,打下扎实基础。精调阶段:针对特定任务(如检索、分类、聚类)进行更精细的训练,确保模型在实际应用中高效表现。2.合成数据+Gemini过滤:低质量样本?不存在的!
为了提升数据质量,研究团队设计了合成数据生成策略,并利用Gemini本身对训练数据进行过滤,彻底剔除低质量样本。这一招确保了模型在训练过程中“吃”的都是“精粮”,有效性直接拉满。
Gemini嵌入模型发布:谷歌的AI竞争力再升级
Gemini嵌入模型的发布,不仅是谷歌在嵌入技术上的一次重要突破,更标志着其在人工智能领域的竞争力进一步增强。随着这一模型的推广,搜索、个性化推荐、内容分析等应用场景都将迎来升级——毕竟,更精准的嵌入向量意味着更高效的信息处理和更个性化的用户体验。
对于独立创作者和自由职业者来说,Gemini嵌入模型的低成本和高性能无疑是一个福音。无论是做内容分类、语义搜索,还是开发多语言应用,这款模型都能提供强有力的支持。
结语:嵌入技术的未来,谷歌已抢占先机
Gemini嵌入模型的登顶,不仅是一场技术竞赛的胜利,更是谷歌在AI领域长期布局的成果。随着模型的逐步落地,我们有理由期待,嵌入技术将在更多场景中发挥关键作用,推动整个行业向前发展。
如果你正在寻找一款高效、经济、多语言的嵌入模型,Gemini绝对值得一试——毕竟,MTEB的榜首位置,可不是随便哪个模型都能坐稳的!
相关推荐
































