Meta神来之笔:AU-Net模型横空出世,或将彻底重塑文本处理格局,大模型时代再添变数!
文章来源:智汇AI 发布时间:2025-07-24
在大语言模型领域,文本处理是关键,传统分词技术却似“枷锁”,局限明显。近日,Meta 放大招,推出创新架构 AU-Net 模型。它打破传统,从原始字节学习,构建多层次序列表示,为文本处理带来新变革,…
暂无访问在大语言模型(LLM)的江湖里,文本处理一直是各路“高手”比拼的关键“招式”。而传统的分词技术,像字节对编码(BytePairEncoding),就像是一套固定的拳法——先把文本切成固定单元,再基于这些单元构建静态词汇表。这招虽然用得广泛,但局限性也不小。一旦分词完成,模型就像被上了枷锁,处理方式没法灵活调整;遇到低资源语言或者特殊字符结构的文本,效果更是大打折扣。
传统分词:看似“万能”,实则“短板”明显
想象一下,你要处理一篇用小众语言写的文章,或者是一段包含大量特殊符号的代码。用传统的分词技术,就像是用一把固定的尺子去量不同形状的物体,总会有些地方量不准。静态词汇表就像是一个封闭的“小世界”,无法适应文本的多样性和变化性。而且,分词过程一旦完成,模型就只能在这个“小世界”里打转,无法根据文本的实际需求灵活调整处理方式。
AU-Net模型是什么?AU-Net登场:从“固定拳法”到“自由搏击”
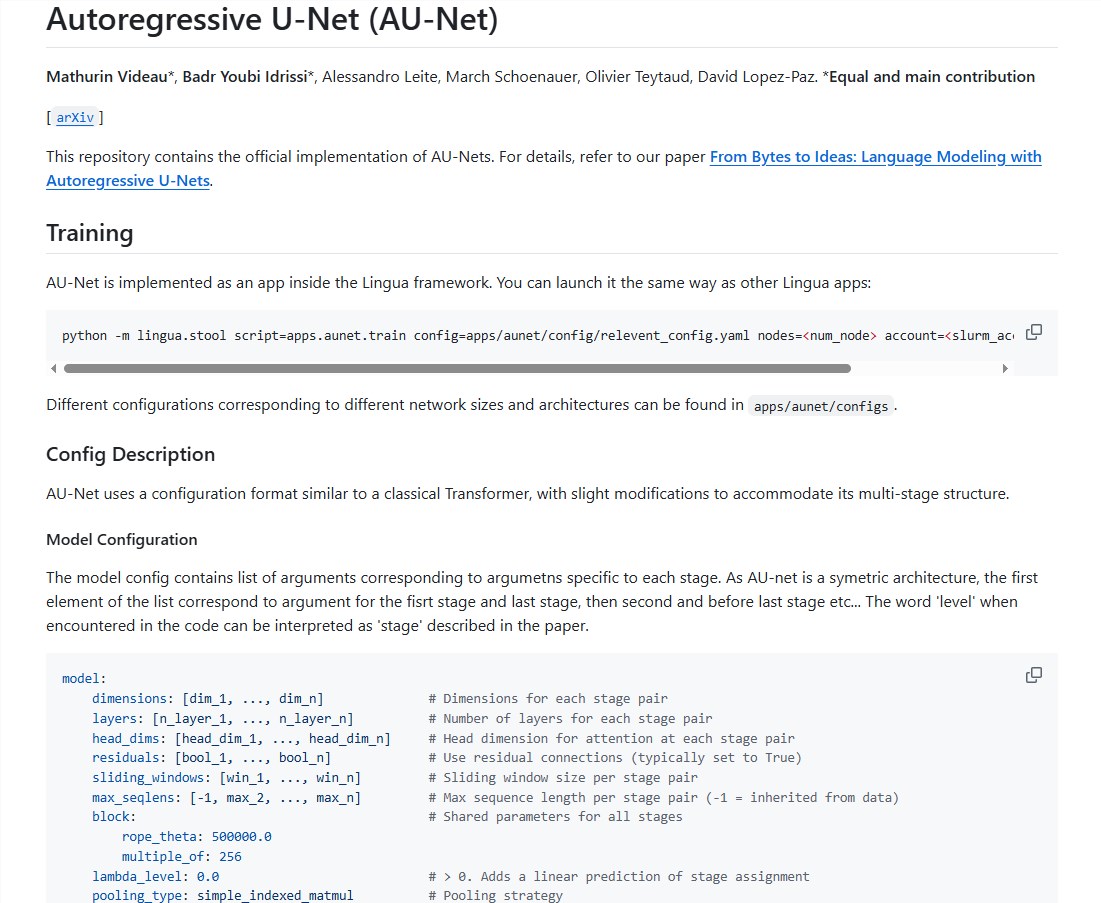
为了打破传统分词的局限,Meta的研究团队推出了AU-Net这个创新模型。它就像是一个“自由搏击高手”,不再局限于固定的分词方式,而是直接从原始字节开始学习,灵活地将字节组合成单词、词组,甚至能形成多达四个单词的组合,构建出多层次的序列表示。
AU-Net开源地址
github地址:https://github.com/facebookresearch/lingua/tree/main/apps/aunet
AU-Net设计的灵感来源:
AU-Net的设计灵感竟然来自医学图像分割领域的U-Net架构!这就像是把医学领域的“手术刀”用到了文本处理上。U-Net架构有独特的收缩路径和扩张路径,AU-Net也借鉴了这一设计。收缩路径就像是一个“压缩器”,把输入的字节序列压缩成更高层次的语义单元,提取文本的宏观语义;扩张路径则像是一个“还原器”,把这些高层次信息逐步还原,恢复到原始序列长度,同时融合局部细节。
AU-Net的收缩路径:分阶段“压缩”,层层递进
AU-Net的收缩路径分为多个阶段,就像是一场“接力赛”。第一阶段,模型直接处理原始字节,用限制注意力机制保证计算的可行性,就像是在给文本“打地基”;第二阶段,模型在单词边界处进行池化,把字节信息抽象成单词级的语义信息,就像是把“砖块”砌成“墙壁”;第三阶段,池化操作在每两个单词之间进行,捕捉更大范围的语义信息,增强模型对文本含义的理解,就像是在“墙壁”上添加“装饰”,让整个结构更稳固、更美观。
AU-Net的扩张路径:多策略“还原”,细节不丢
扩张路径则负责把压缩后的信息逐步还原。它采用多线性上采样的策略,让每个位置的向量能根据序列中的相对位置进行调整,优化高层次信息和局部细节的融合。就像是一个“拼图高手”,把分散的碎片拼成完整的图片。此外,跳跃连接的设计保证了在还原过程中不丢失重要的局部细节信息,就像是在拼图时不会漏掉任何一块碎片,从而提升模型的生成能力和预测准确性。
AU-Net的推理阶段:自回归生成,连贯又高效
在推理阶段,AU-Net采取自回归的生成机制,就像是一个“讲故事的高手”,确保生成的文本既连贯又准确,同时提高了推理效率。这种创新架构为大语言模型的发展提供了新的思路,展现了更强的灵活性和适用性。无论是处理小众语言、特殊符号,还是应对复杂的文本场景,AU-Net都能游刃有余。
结语:AU-Net,大语言模型的“新引擎”
Meta推出的AU-Net模型,就像是一股清流,为大语言模型的文本处理带来了新的活力。它打破了传统分词的局限,让模型能够更灵活、更高效地处理文本。对于开发者来说,AU-Net是一个值得探索的新工具;对于整个行业来说,它或许会成为推动大语言模型发展的“新引擎”。
未来,我们期待看到更多像AU-Net这样的创新模型,让AI技术更好地服务于我们的生活。
相关推荐
































