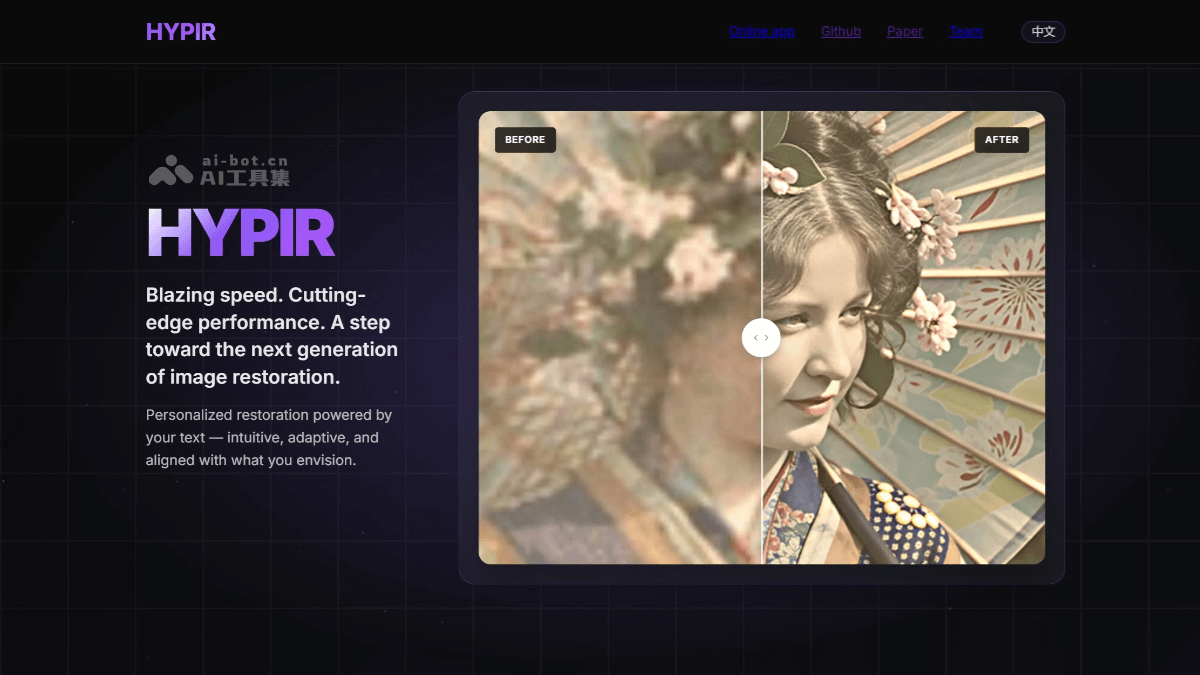
Vidu的AI算法是如何工作的
文章来源:智汇AI 发布时间:2024-11-22
Vidu的AI算法通过融合Diffusion和Transformer技术,并基于U-ViT架构进行工作,从而实现了高效、高质量的视频生成。
暂无访问Vidu的AI算法是如何工作的?以下是关于Vidu AI算法工作原理的详细解释:
一、核心技术
-
Diffusion技术:
- Diffusion是一种生成模型,通过逐步引入噪声并逆转这个过程来生成数据。
- 在Vidu中,Diffusion技术负责生成视频的每一帧,确保画面的连贯性和逼真度。
-
Transformer技术:
- Transformer是一种深度学习模型,最初用于处理自然语言,但近年来在图像和视频生成领域也取得了显著成果。
- 在Vidu中,Transformer负责理解文本描述,并将其转化为视频的视觉元素。
二、U-ViT架构
U-ViT是Vidu的核心架构,由生数科技提出,并早于Sora的DiT架构。U-ViT架构的优势在于能够更好地模拟真实世界的物理原理,同时保持视频中主体的一致性。以下是U-ViT架构的工作流程:
-
视频自编码器:
- Vidu首先采用视频自编码器(Video Autoencoder)来压缩视频的空间和时间特征,保证能够进行视频维度的处理。
-
U-ViT噪声预测网络:
- 接下来,Vidu使用U-ViT作为噪声预测网络进行特征的处理。
- U-ViT将压缩视频分割成3D-patched(三维补丁),并将所有输入(包括时间、文本条件和噪声3D补丁)视为token(标记)。
- 在Transformer的浅层和深层之间,U-ViT采用长跳跃连接,以更好地捕捉视频中的信息。
-
Transformer处理变长序列:
- 通过利用Transformer处理变长序列的能力,Vidu能够处理具有可变时长的视频。
三、训练与优化
-
训练数据:
- Vidu在大量的文本-视频对上进行了训练,这使得它能够理解文本描述与视频内容之间的关联。
-
算法优化:
- 在论文中,Vidu加入了对视频描述的Re-captioning(重新描述)的算法优化,可以使用模型自动为所有训练视频添加标注,从而进一步提高生成视频的质量。
四、功能特点
基于上述算法和工作原理,Vidu具有以下功能特点:
- 模拟真实物理世界:生成画面符合真实的物理规律,如合理的光影效果、细腻的人物表情等。
- 时空一致性:随着镜头的移动,人物和场景在时间、空间中能够保持一致。
- 多镜头语言:能够生成复杂的动态镜头,在一段画面里实现远景、中景、近景、特写等不同镜头的切换。
- 具有丰富想象力:能够生成真实世界不存在的虚构画面,创造出具有深度和复杂性的内容。
- 理解中国元素:能够理解并生成特有的中国元素画面。
综上所述,Vidu的AI算法通过融合Diffusion和Transformer技术,并基于U-ViT架构进行工作,从而实现了高效、高质量的视频生成。
相关推荐