StreamSpeech-流媒体语音输入的实时翻译模型
文章来源:智汇AI 发布时间:2025-03-11
StreamSpeech:流媒体语音输入的实时翻译模型_映技派,专注ai人工智能!,StreamSpeech,一个可以实现流媒体语音输入的实时翻译模型,可以在实时通信中将语音即时翻译成另一种语言,同时输出对应的目标语音。
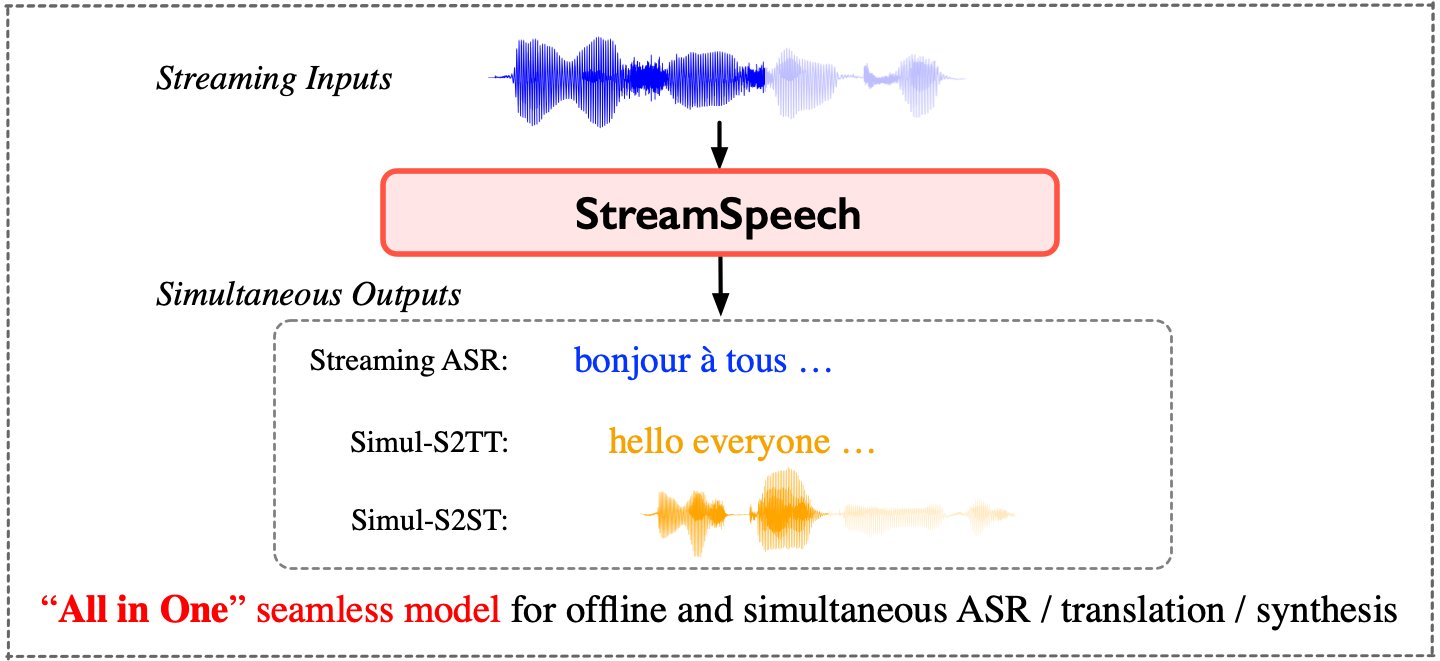
暂无访问StreamSpeech,一个可以实现流媒体语音输入的实时翻译模型,用于离线和同步语音识别、语音翻译和语音合成。它可以在实时通信中将语音即时翻译成另一种语言,同时输出对应的目标语音。
它不仅能将语音翻译成另一种语言,还能将语音内容实时转录为文本。用户可以同时获得语音和文本两种形式的翻译结果,而且翻译过程是同步进行的,无需等待整个语音输入结束,从而实现低延迟的实时翻译。
StreamSpeech还能在翻译过程中展示实时的语音识别结果,帮助用户即时了解翻译进度。
StreamSpeech还可以无缝集成到各种应用和设备中,如翻译耳机、会议系统、直播平台等,为用户提供便捷的翻译服务。无论是在个人设备上使用,还是在大型会议系统中应用,Simul-S2ST都能提供稳定的性能。
StreamSpeech应用场景:
国际会议中,使用StreamSpeech进行同声传译。
跨国公司使用StreamSpeech进行远程会议,实现实时多语言沟通。
语言学习者使用StreamSpeech练习不同语言的听力和口语。
StreamSpeech亮点:
StreamSpeech 在离线和同步语音到语音翻译方面均实现了 SOTA 性能。
StreamSpeech 通过“一体化”无缝模型执行流式 ASR、同步语音到文本翻译和同步语音到语音翻译。
StreamSpeech可以在同声翻译过程中呈现中间结果(即ASR或翻译结果),提供更全面的低延迟通信体验。
StreamSpeech非常适用于需要实时跨语言交流的专业人士。它通过减少翻译延迟,使得不同语言背景的人们能够无障碍地进行实时对话。"
官网:https://ictnlp.github.io/StreamSpeech-site/
Github:https://github.com/ictnlp/StreamSpeech
论文:https://arxiv.org/abs/2406.03049
相关推荐