



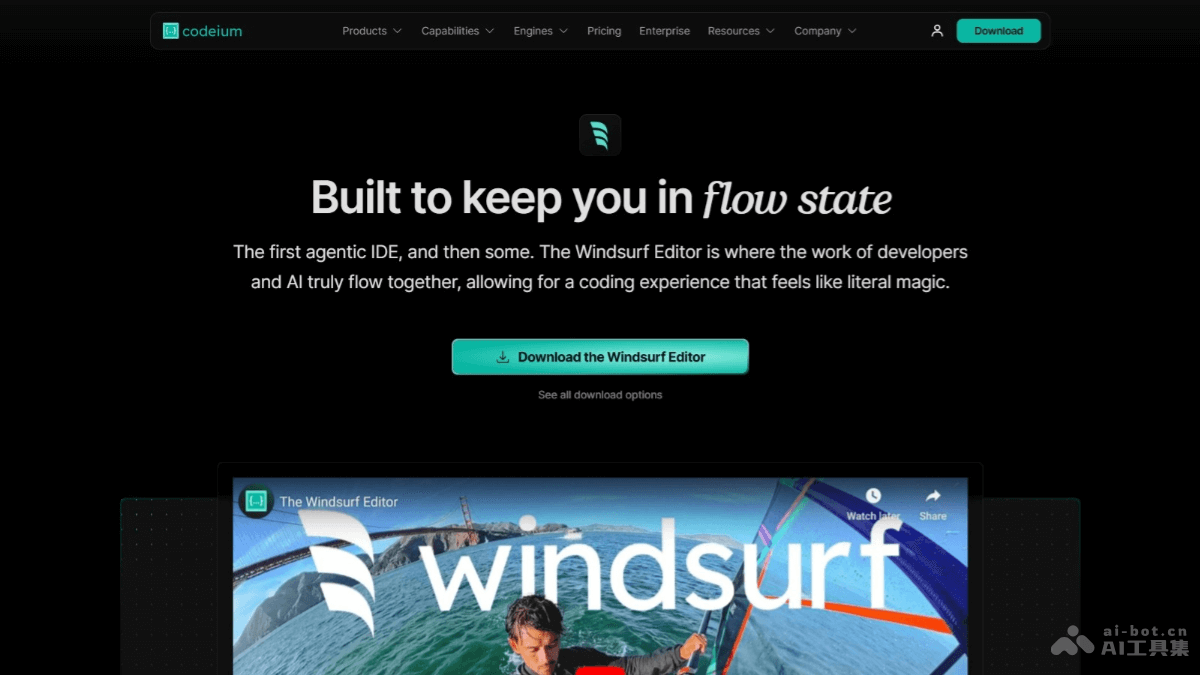
Windsurf-Co
Windsurf 是Code
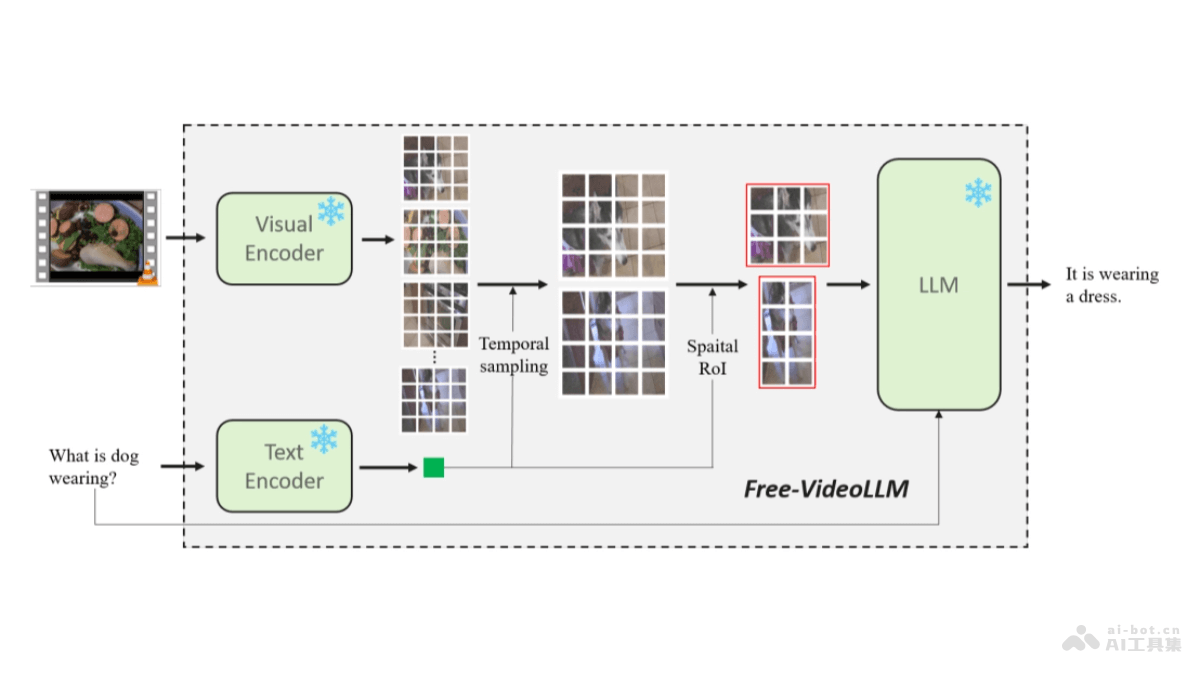
Free Video-
Free Video-LLM
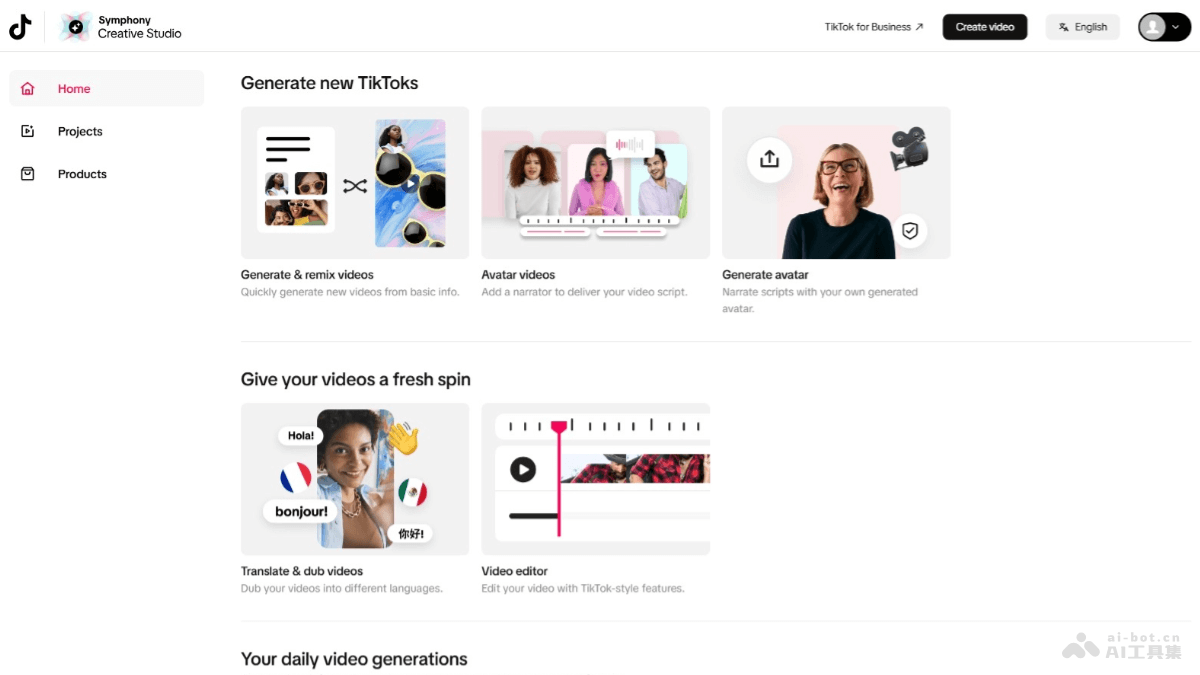
Symphony Cr
Symphony Creat

Skywork o1-
Skywork o1是昆仑万
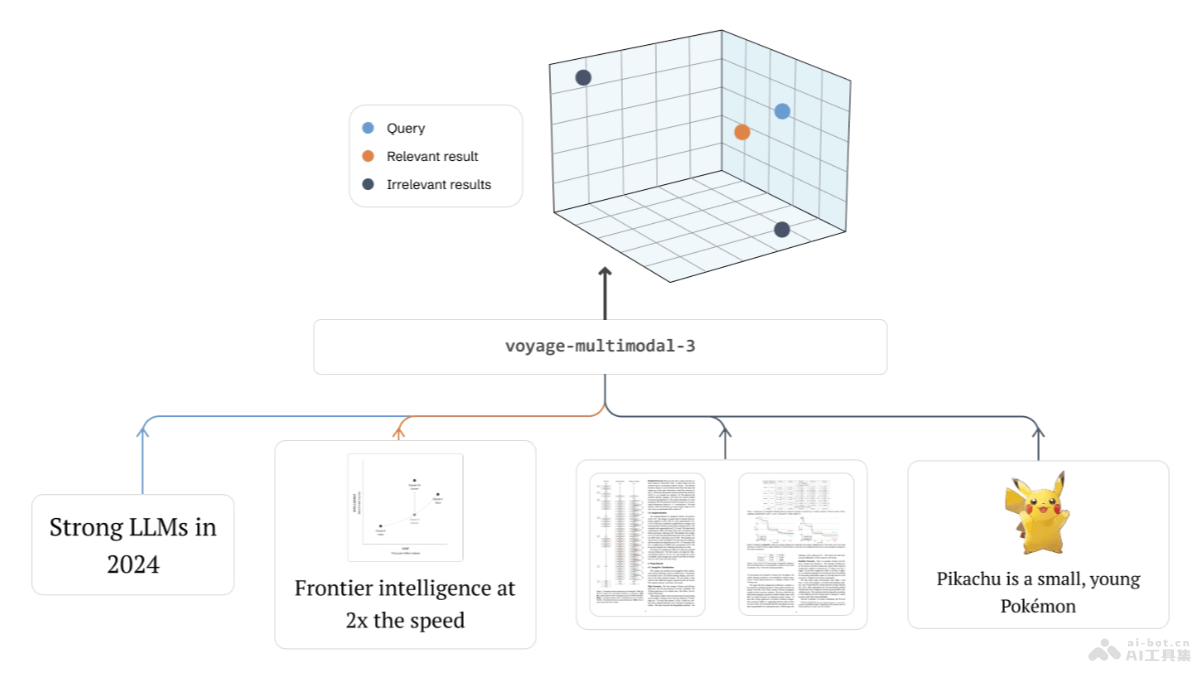
Voyage Mult
Voyage Multimo
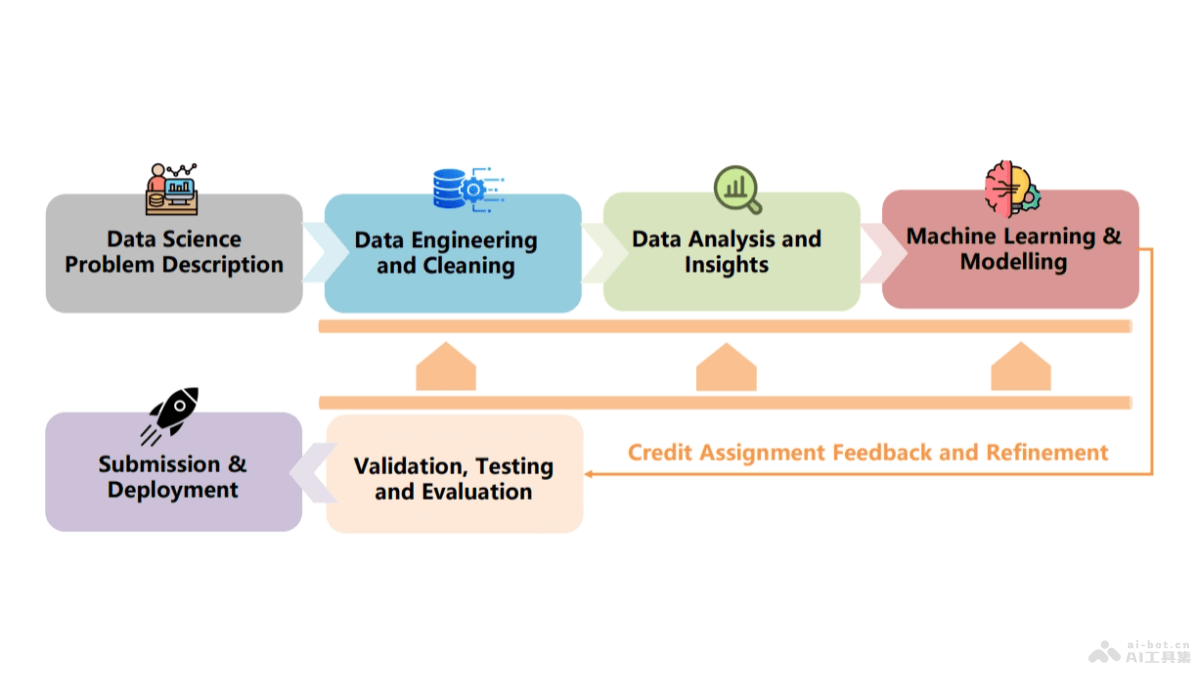
Agent K v1.
Agent K v1.0 是

Pixtral Lar
Pixtral Large是

Qwen2.5-Tur
Qwen2.5-Turbo是

PixelWave F
PixelWave Flux
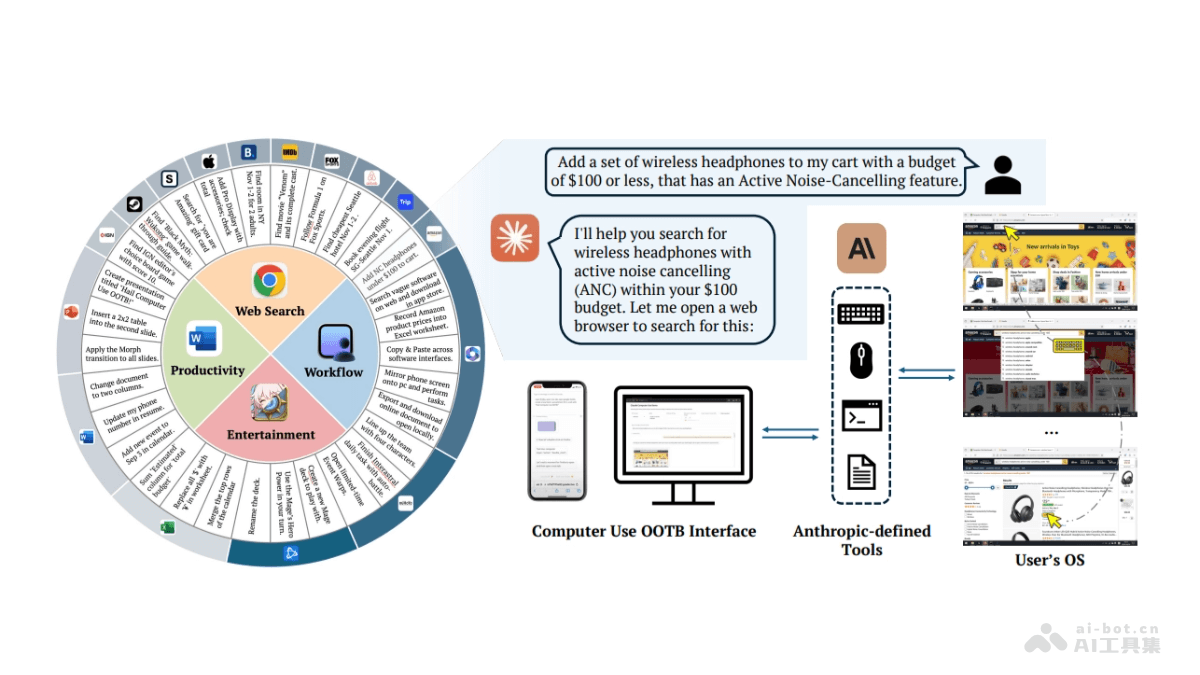
Computer Us
Computer Use O

Fireworks f
Fireworks f1是F

Memoripy-支持
Memoripy是一个Pyt
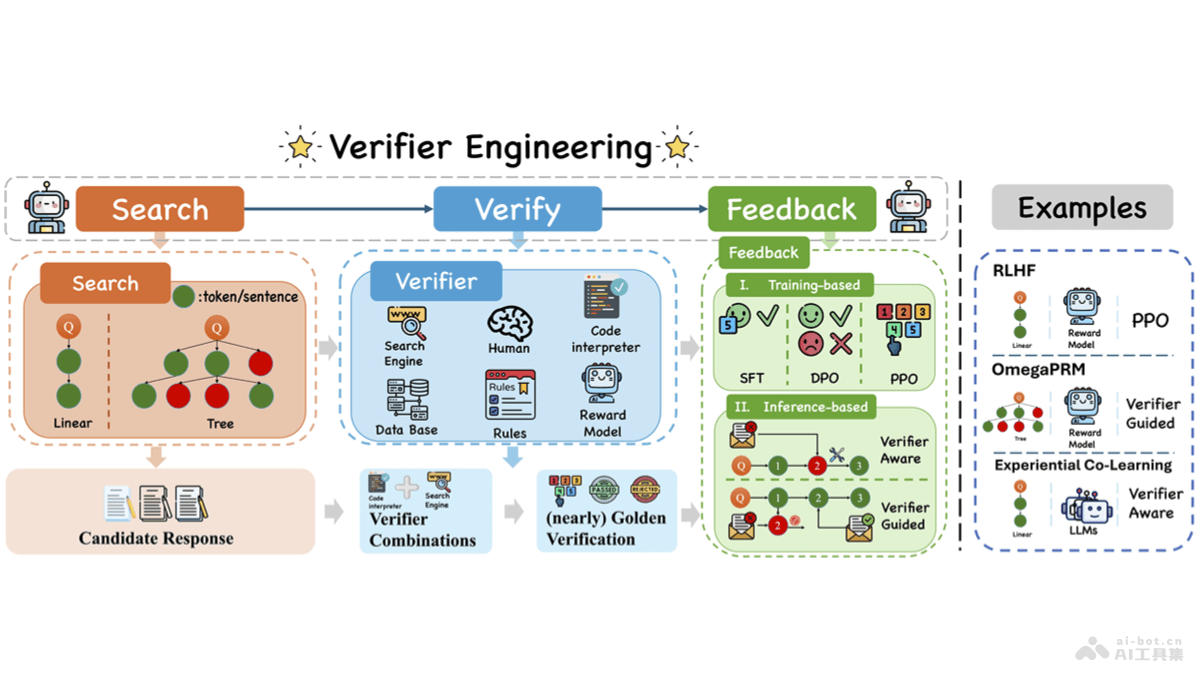
Verifier En
Verifier Engin
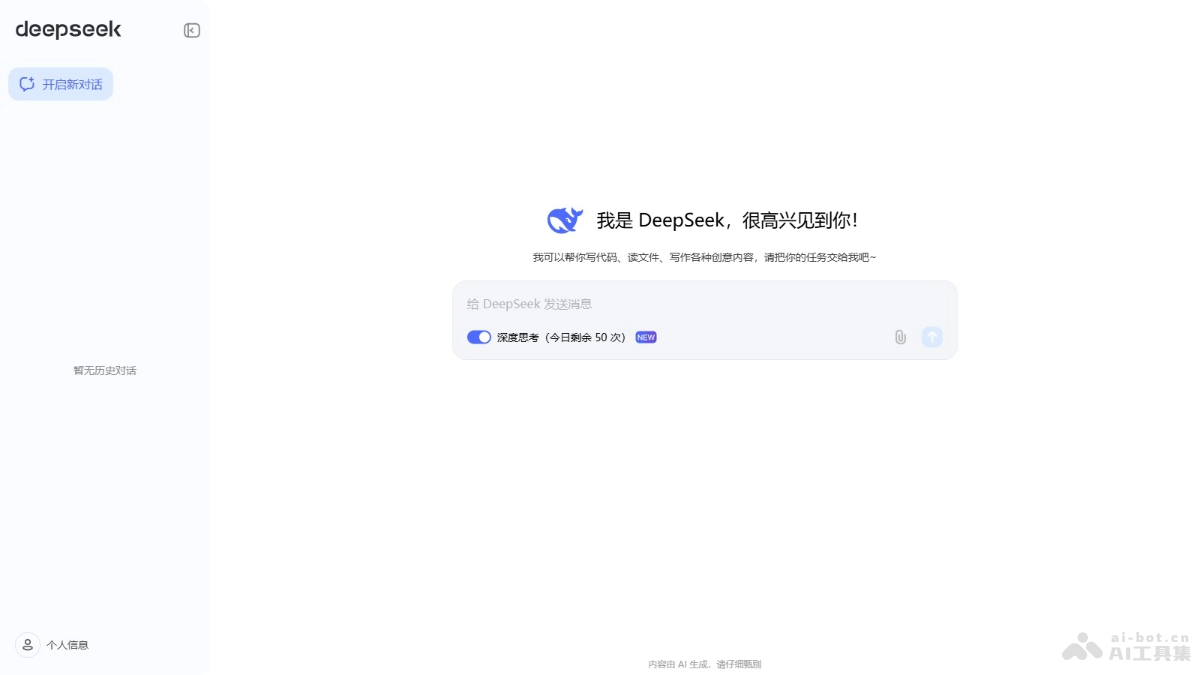
DeepSeek-R1
DeepSeek-R1-Li

Samsung Gau
Samsung Gauss2
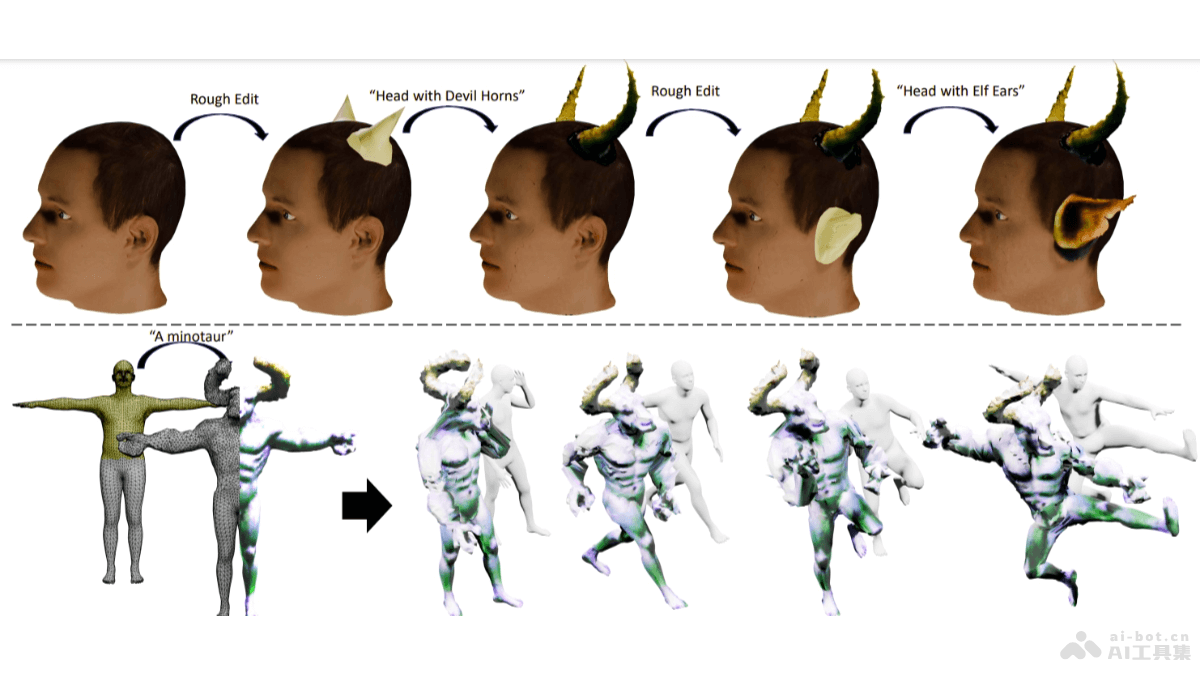
MagicClay-A
MagicClay 是 Ad

FLUX Tools-
FLUX Tools是黑森林
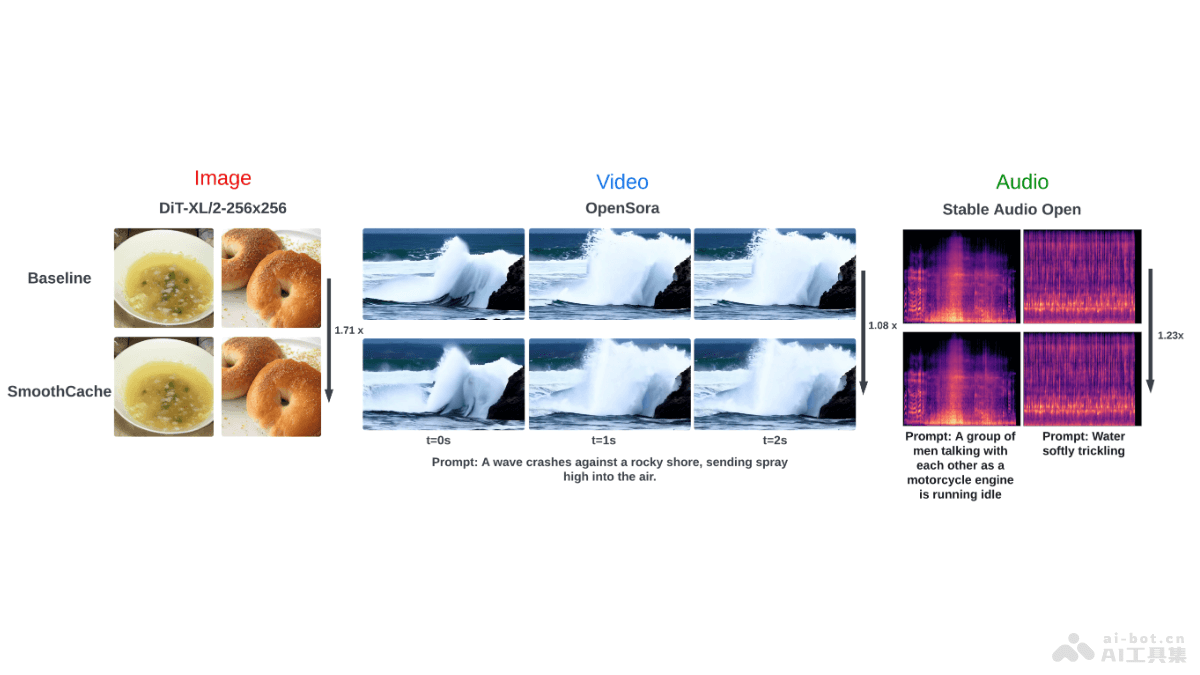
SmoothCache
SmoothCache 是用

In-Context
In-Context LoR

DINO-X-IDEA
DINO-X是IDEA研究院

The Matrix-
The Matrix是与电影
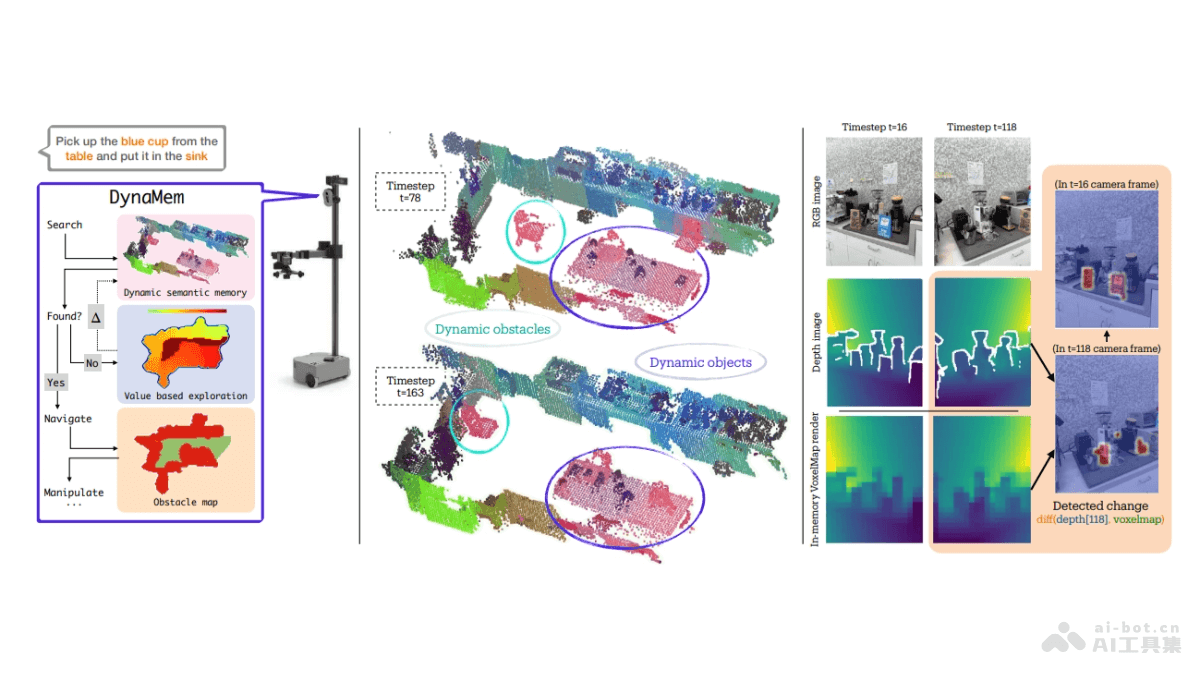
DynaMem-纽约大
DynaMem是纽约大学和H

LTX Video-L
LTX Video是Ligh

Markdown-to
Markdown-to-Im

TÜLU 3-Ai2
TÜLU 3是艾伦人工智能研

Flex3D-Meta
Flex3D是由Meta的G

MCP-Anthrop
MCP(Model Cont
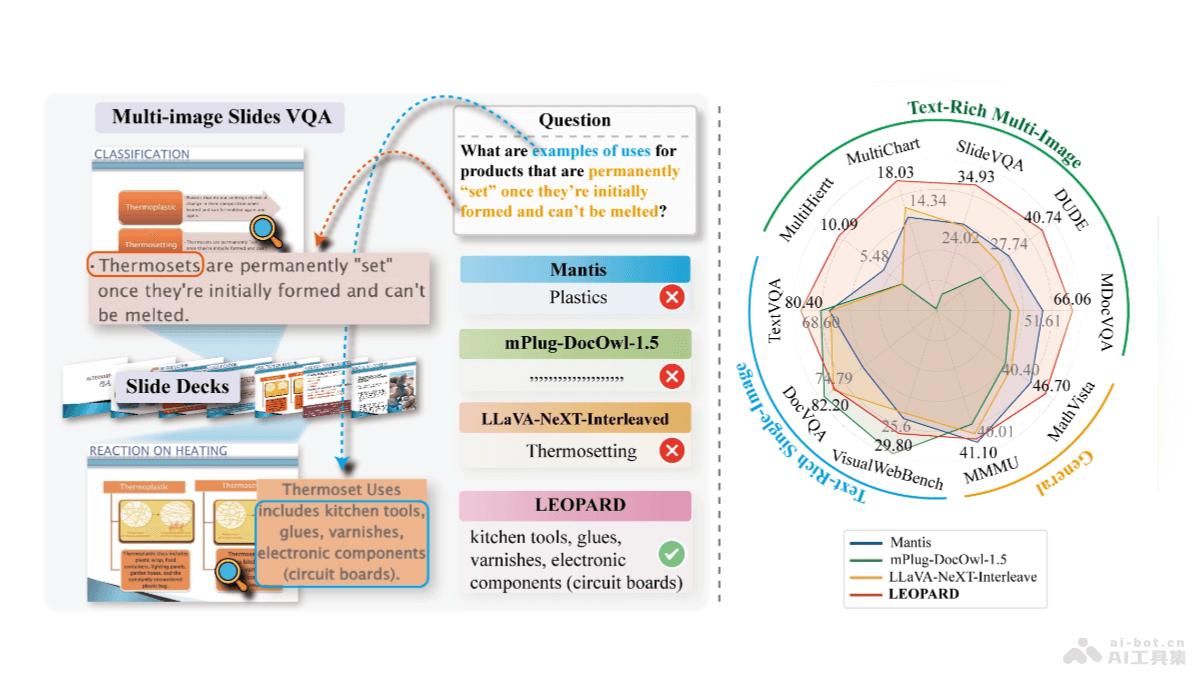
LEOPARD-腾讯A
LEOPARD是腾讯AI L
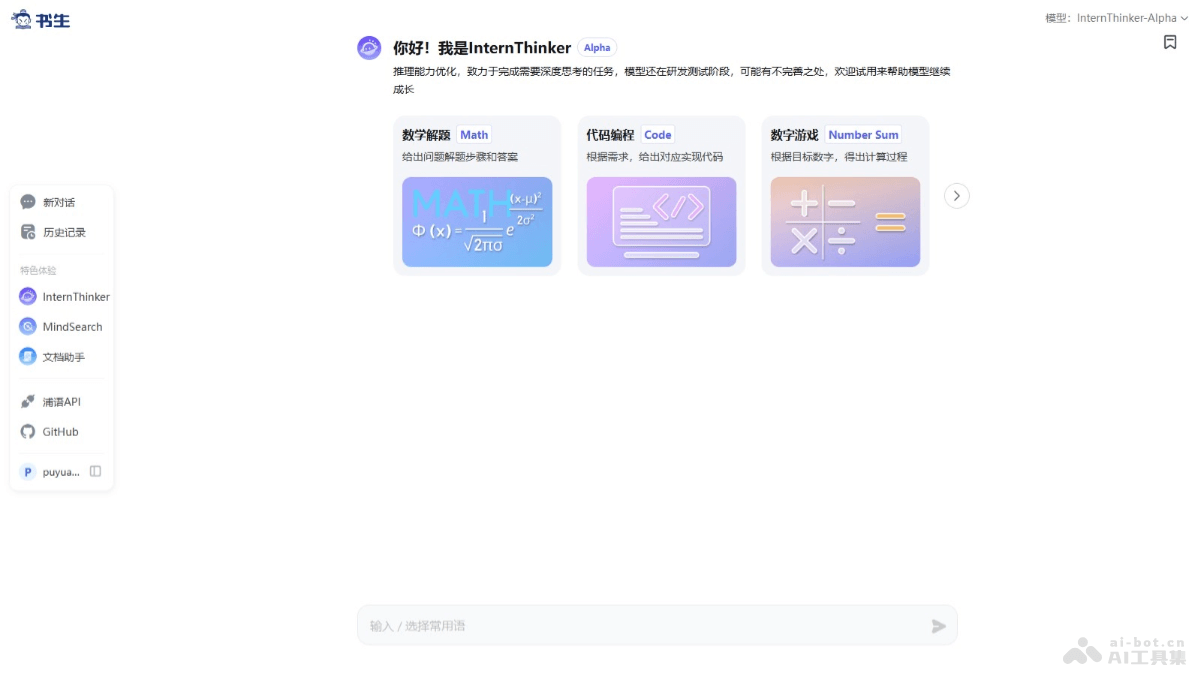
书生InternThi
书生InternThinke

SlideChat-上
SlideChat是上海AI

Edify 3D-NV
Edify 3D 是 NVI

DynaSaur-Ad
DynaSaur是Adobe

Takin Audio
Takin AudioLLM

AutoTrain-H
AutoTrain(Auto
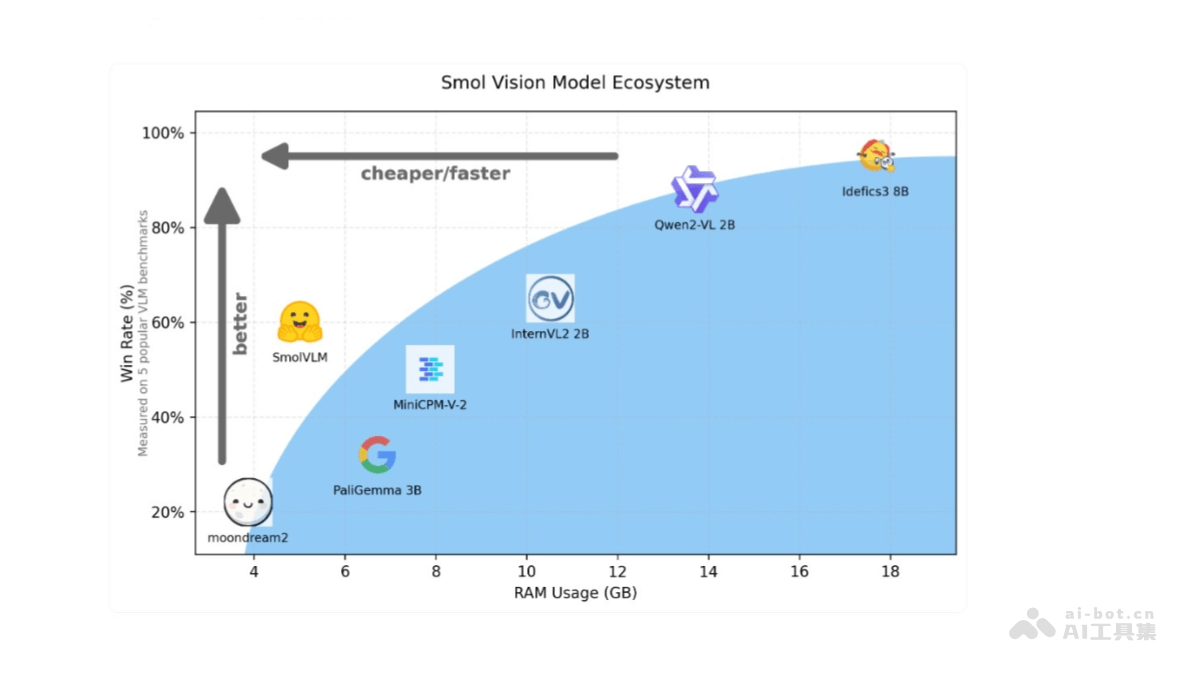
SmolVLM-Hug
SmolVLM是Huggin
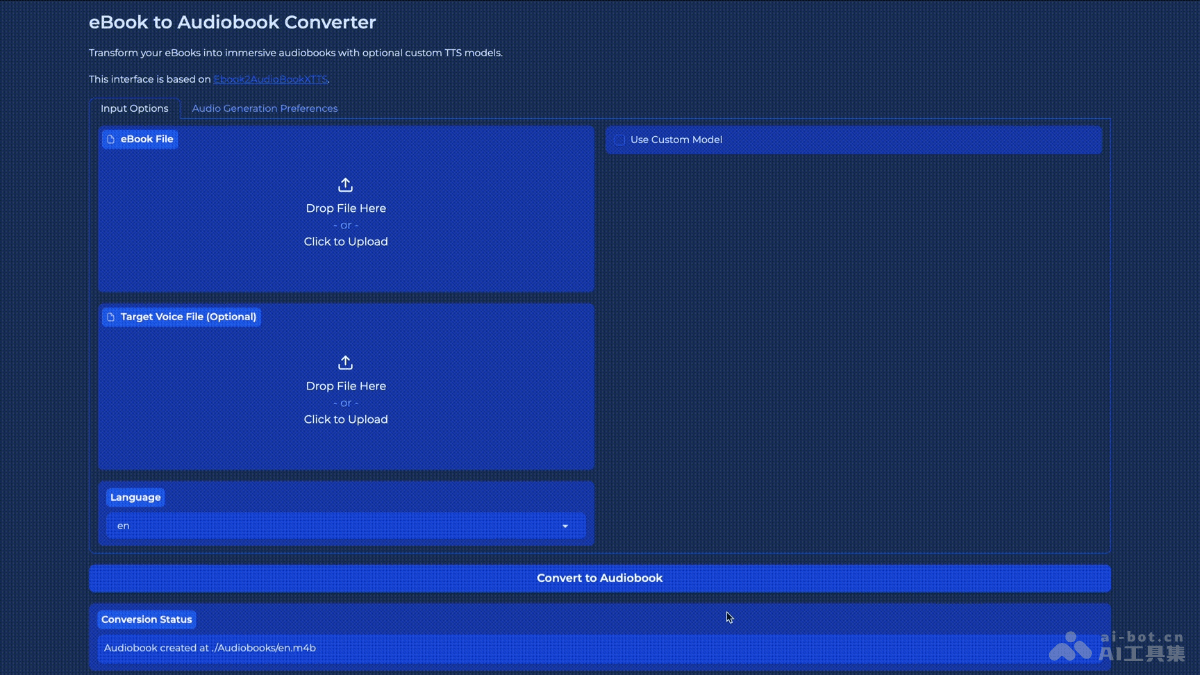
ebook2audio
ebook2audioboo