




胜利女神新的希望积分商
在胜利女神新的希望这款游戏中

胜利女神新的希望米哈拉
小编今天带来的是胜利女神新的

胜利女神新的希望拉毗技
今天小编给大家带来的是胜利女

胜利女神新的希望阿尼斯
本期带来的是胜利女神新的希望

胜利女神新的希望铁匠打
在游戏中,玩家将遇到很多强势

胜利女神新的希望无限之
无限之塔在游戏中是一个比较有

胜利女神新的希望芯尘如
对于新手玩家而言,要想快速的

胜利女神新的希望一举歼
对于新手玩家而言,要想迅速的

胜利女神新的希望战役难
在游戏中除了常见的主线关卡之

胜利女神新的希望指挥中
玩家在解锁前哨基地时,除了指
胜利女神新的希望快速战
胜利女神新的希望快速战斗怎么

胜利女神新的希望珠宝如
刚刚体验这款游戏的朋友就应该
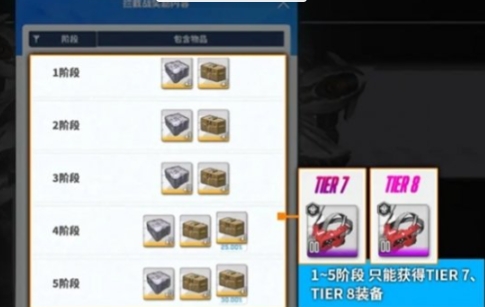
胜利女神新的希望装备获
在游戏中,玩家要想尽快地提升

胜利女神新的希望作战出
作战出击就是个人突袭,在25

胜利女神新的希望强度榜
胜利女神新的希望这款游戏在最

胜利女神新的希望迪塞尔
胜利女神新的希望迪塞尔,是游

胜利女神新的希望小美人
胜利女神新的希望小美人鱼的具

胜利女神新的希望国服上
在众多玩家的热切期盼中,胜利

胜利女神新的希望铁匠打
胜利女神新的希望,这款游戏对

胜利女神新的希望露姬玩
胜利女神新的希望,这款游戏中
胜利女神新的希望21章
在胜利女神新的希望21章bo
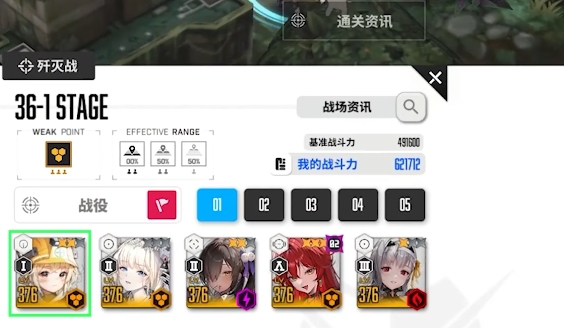
胜利女神新的希望爆裂技
在胜利女神新的希望世界里,爆

胜利女神新的希望贝伊是
在胜利女神新的希望游戏中,贝

胜利女神新的希望艾德米
在胜利女神新的希望游戏里,艾

胜利女神新的希望iDo
在胜利女神新的希望游戏世界里

胜利女神新的希望艾可希
在近期风靡全球的射击手游胜利
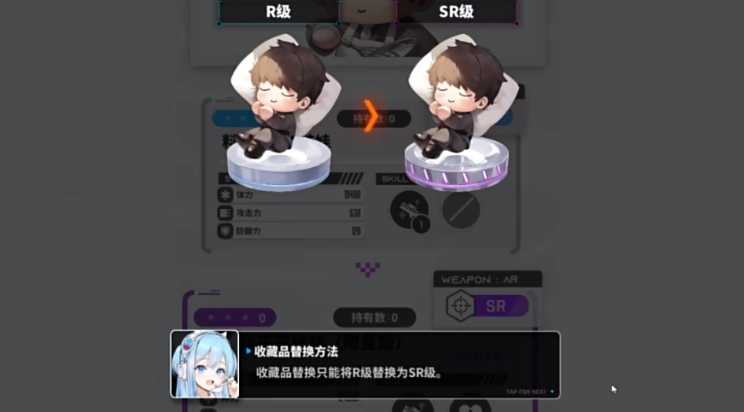
胜利女神新的希望专用收
在胜利女神新的希望这款手游世

胜利女神新的希望202
在胜利女神新的希望世界里,角

胜利女神新的希望阿尼斯
在胜利女神新的希望游戏世界里

胜利女神新的希望艾丽卡
艾丽卡这个名字在胜利女神新的

胜利女神新的希望杨强度
在胜利女神新的希望那充满热血

胜利女神新的希望异端者
在胜利女神新的希望游戏世界里

胜利女神新的希望抽卡概
在胜利女神新的希望游戏中,其
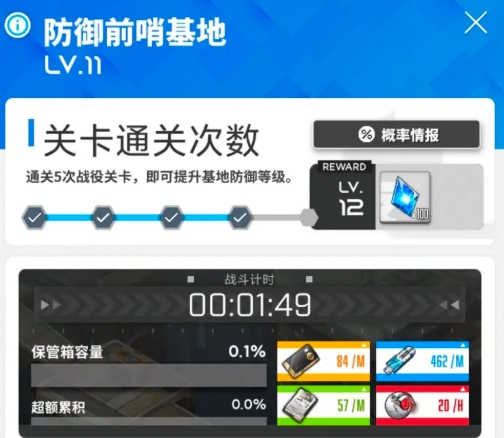
胜利女神新的希望副本攻
在胜利女神新的希望游戏中,大

胜利女神新的希望氪金吗
对刚刚踏入胜利女神新的希望这
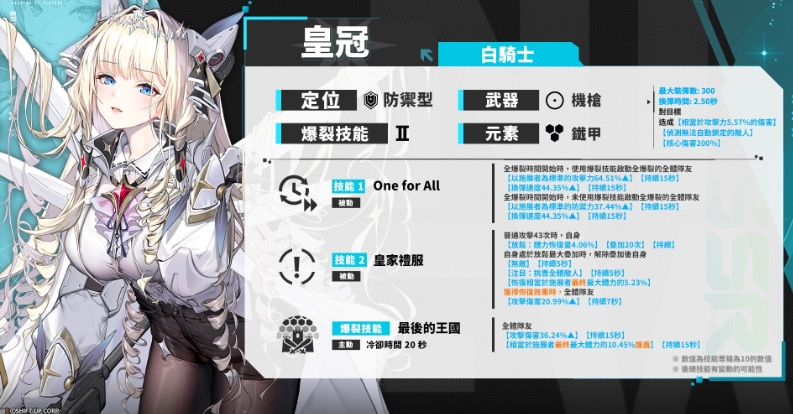
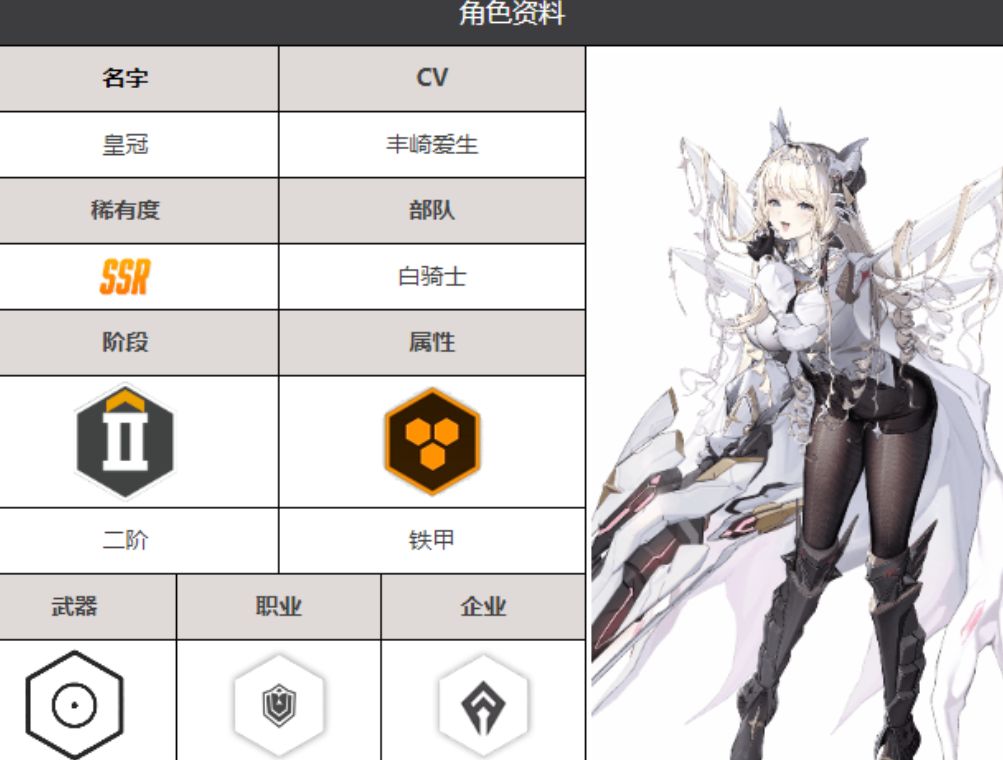
胜利女神新的希望皇冠强
在胜利女神新的希望动态枪战游