字节跳动开源3亿参数的VINCIE-3B模型:支持上下文连续图像编辑
文章来源:智汇AI 发布时间:2025-07-04
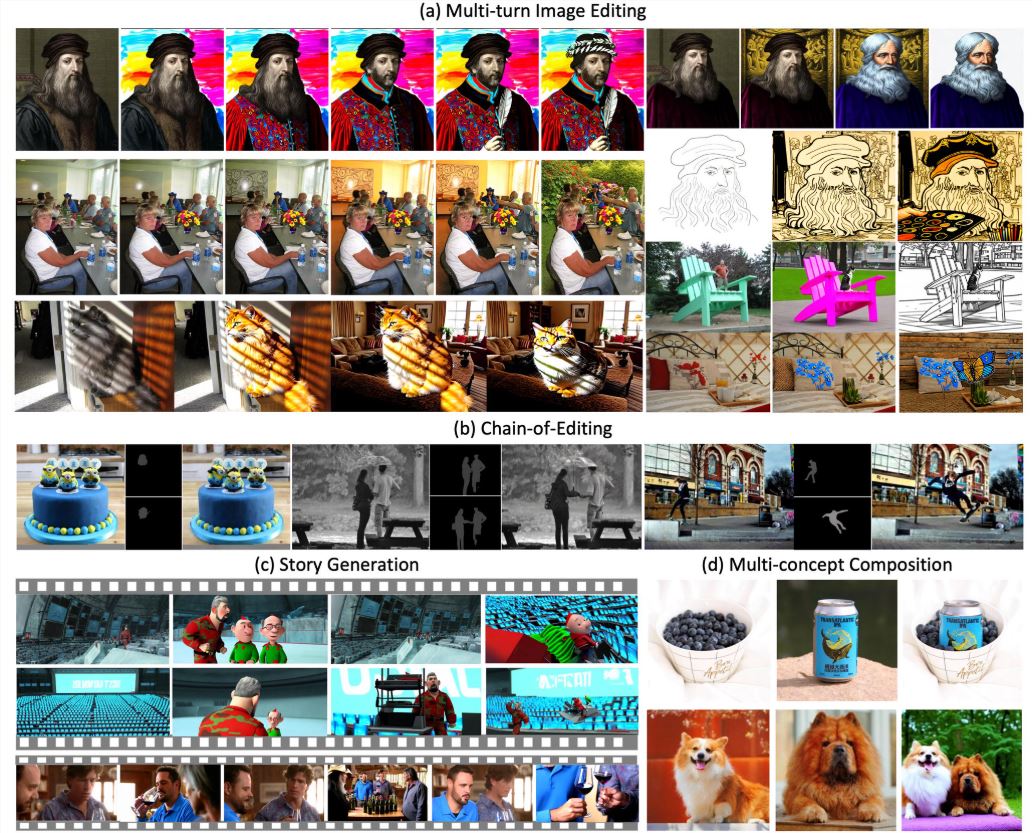
在图像编辑领域,传统模型因依赖复杂数据管道、成本高且流程繁琐而受限。近日,字节跳动开源VINCIE - 3B模型,它拥有3亿参数,基于MM - DiT架构,能从视频中挖掘上下文编辑潜力,性能卓越且开…
暂无访问VINCIE-3B模型是什么?
字节跳动开源的VINCIE-3B是一款拥有3亿参数、支持上下文连续图像编辑的先进模型,基于其内部MM-DiT架构开发。该模型突破了传统图像编辑的局限,首次实现从单一视频数据中学习上下文感知的图像编辑能力,无需依赖复杂的分割或修复模型生成训练数据。通过视频驱动训练、块因果扩散变换器、三重代理任务训练等技术,VINCIE-3B在文本遵循性、角色一致性和复杂场景编辑(如动态物体移动)上表现优异,生成高质量编辑图像的平均时间约为4秒,推理效率比同类模型快约8倍,为创意设计、影视后期及内容生成领域带来了全新的可能性。
模型地址:https://huggingface.co/ByteDance-Seed/VINCIE-3B
技术突破:摆脱传统数据依赖
传统图像编辑模型通常需要借助任务特定的数据管道,依靠专家模型(如分割、修复模型)来生成训练数据。这一过程不仅成本高昂,而且流程极为复杂。而VINCIE-3B实现了创新突破,它能够直接从视频中学习,通过将视频转化为交错多模态序列(包含文本和图像),达成上下文感知的图像编辑,彻底摆脱了对专家模型的依赖,大大降低了数据准备成本。
独特技术亮点
视频驱动训练:VINCIE-3B巧妙利用视频的连续帧,自动提取文本描述与图像序列,进而构建多模态训练数据。这种方法避免了传统方式对专家模型的过度依赖,让数据准备变得更加轻松高效。块因果扩散变换器:该模型采用了块因果注意力机制,在文本和图像块之间实现因果注意力,而在块内则是双向注意力。这种精妙的设计确保了信息能够高效流动,同时还能保持时间序列的因果一致性,为图像编辑提供了更稳定的支持。三重代理任务训练:VINCIE-3B通过下一帧预测、当前帧分割预测和下一帧分割预测这三种任务进行训练。这种多元化的训练方式增强了模型对动态场景和物体关系的理解能力,使其在处理复杂图像编辑任务时更加得心应手。干净与噪声条件结合:为了解决扩散模型中噪声图像输入的问题,VINCIE-3B同时输入干净和噪声图像标记,并利用注意力掩码确保噪声图像仅基于干净上下文进行条件生成。这一创新举措有效提升了图像编辑的质量,让生成的图像更加逼真。
性能表现卓越
在性能测试中,VINCIE-3B在KontextBench和新型多轮图像编辑基准测试中均达到了业界领先水平(SOTA)。尤其在文本遵循性、角色一致性和复杂场景编辑(如动态物体移动)方面表现出色。而且,生成一张高质量编辑图像的平均时间约为4秒,推理效率比同类模型快约8倍,大大提高了工作效率。
开源生态:开源资源发布
2025年6月14日,VINCIE-3B的完整代码、模型权重及训练数据处理流程在GitHub和arXiv上正式发布。开发者可以通过申请获取完整数据集(联系邮箱:yangsiqian@bilibili.com)。该模型基于字节跳动的MM-DiT(3B和7B参数版本)初始化,采用Apache2.0许可证,支持非商业用途,商业应用则需联系字节跳动获取许可。
推动社区发展
字节跳动还推出了一个多轮图像编辑基准测试,其中包含了丰富的真实场景用例,鼓励社区开发者验证和优化模型性能。这一举措得到了社交媒体上开发者的热烈欢迎,他们认为VINCIE-3B“从视频学习”的方法为低成本AI内容创作开辟了一条崭新的路径。
应用场景:影视后期制作
在影视后期领域,VINCIE-3B可以从视频帧中提取角色或物体,并进行连续编辑,使其能够完美适配不同的场景。例如,将角色从室内移到室外,同时保持光影和视角的一致性,为影视制作带来了更高的效率和更好的效果。
品牌营销推广
对于品牌营销而言,VINCIE-3B可以将产品或Logo轻松置入不同的背景中,如咖啡店、户外广告牌等,并自动调整光照、阴影和透视效果,大大简化了多场景宣传素材的制作流程,节省了时间和成本。
游戏与动画创作
在游戏和动画领域,通过文本指令,VINCIE-3B可以方便地调整角色动作或场景元素,支持快速原型设计和动画预览,为创作者提供了更多的创意空间和更高效的工作方式。
社交媒体内容创作
社交媒体创作者也可以借助VINCIE-3B的强大功能,基于单张图像生成动态序列,如将静态角色图像转化为动态表情包,为社交媒体内容增添更多趣味性和吸引力。
例如,当给出提示“将穿红裙的女孩从公园移到海滩,保持裙子纹理,调整为夕阳光照”时,VINCIE-3B能够生成自然融合的图像,裙子细节和光影效果高度逼真。测试显示,在多轮编辑中,VINCIE-3B能保持90%以上的角色一致性,优于FLUX.1Kontext[pro]在复杂场景下的表现。
局限与挑战:多轮编辑限制
尽管VINCIE-3B表现出色,但在过多轮次的编辑时,可能会引入视觉伪影,导致图像质量下降。因此,建议用户在5轮以内完成编辑,以保持最佳效果。
语言支持不足
目前,该模型主要支持英文提示,对于中文和其他语言的文本遵循性稍逊一筹。字节跳动计划在后续版本中优化多语言能力,以满足更广泛用户的需求。
版权问题待解
训练数据部分来自公开视频,这可能存在潜在的版权争议。用户在商业应用中需确保内容合规,避免不必要的法律风险。
建议用户在使用VINCIE-3B时,结合其提供的KontextBench数据集进行测试,优化提示设计。对于商业用户,建议联系字节跳动明确许可条款。
行业影响:引领图像编辑新范式
VINCIE-3B的发布标志着图像编辑从静态到动态、从单一到上下文连续的范式转变。与BlackForestLabs的FLUX.1Kontext(专注于静态图像编辑)相比,VINCIE-3B通过视频学习实现了更强的动态场景理解,特别适合需要时间序列一致性的应用。相比Bilibili的AniSoraV3(专注于动漫视频生成),VINCIE-3B更加通用,能够覆盖现实场景和虚拟内容生成。
字节跳动的开源策略进一步巩固了其在AI创意工具领域的领先地位。VINCIE-3B的“视频到图像”训练方法有望启发其他公司探索类似路径,降低AI模型开发成本,推动创意产业的民主化发展。
未来,我们有理由期待图像编辑领域将迎来更多的创新和突破。
相关推荐
































