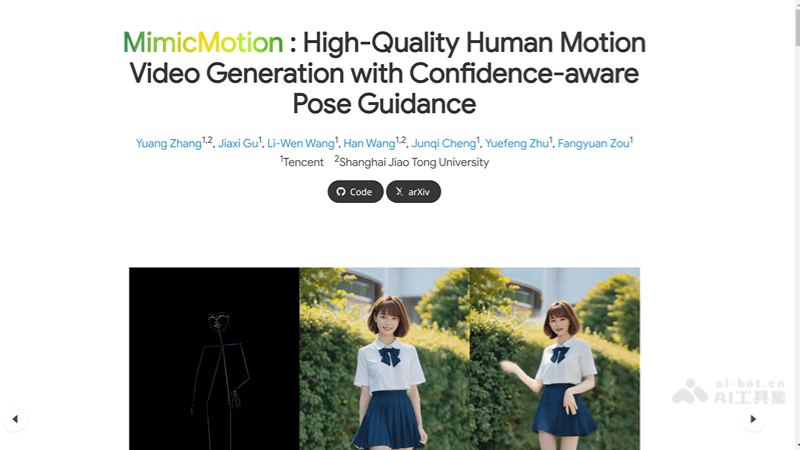
MimicMotion-腾讯推出的AI人像动态视频生成框架
文章来源:智汇AI 发布时间:2025-08-05
MimicMotion是腾讯的研究人员推出的一个高质量的人类动作视频生成框架,利用置信度感知的姿态引导技术,确保视频帧的高质量和时间上的平滑过渡。此外,Mimi
暂无访问MimicMotion是什么
MimicMotion是腾讯的研究人员推出的一个高质量的人类动作视频生成框架,利用置信度感知的姿态引导技术,确保视频帧的高质量和时间上的平滑过渡。此外,MimicMotion通过区域损失放大和手部区域增强,显著减少了图像失真,提升了人像手部动作的细节表现。该框架还能通过渐进式潜在融合策略生成长视频,能够生成高质量、长时间且符合特定动作指导的人类动作视频,同时显著提高了视频生成的控制性和细节丰富度。
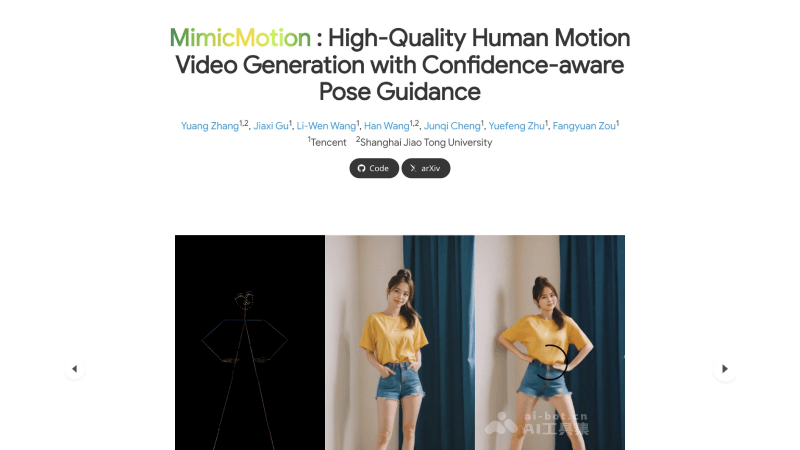
MimicMotion的功能特点
生成多样化视频:MimicMotion能够根据用户提供的姿态指导生成各种动作的视频内容。无论是舞蹈、运动还是日常活动,只要提供相应的姿态序列,MimicMotion都能够创造出相应的动态视频。控制视频长度:用户可以根据自己的需求指定视频的持续时间,MimicMotion能够生成从几秒钟的短片段到几分钟甚至更长的完整视频,提供灵活性以适应不同的应用场景。姿态引导控制:框架使用参考姿态作为条件,确保生成的视频内容在动作上与指定的姿态保持一致。MimicMotion允许用户对视频的动作进行精确控制,实现高度定制化的视频生成。细节质量保证:MimicMotion特别关注视频中的细节,尤其是手部等容易失真的区域。通过置信度感知的策略,系统能够在这些区域提供更清晰的视觉效果。时间平滑性:为了提供更自然的观看体验,MimicMotion确保视频帧之间的过渡平滑,避免出现卡顿或不连贯的现象,使得视频看起来更加流畅自然。减少图像失真:通过置信度感知的姿态引导,MimicMotion能够识别并减少由于姿态估计不准确导致的图像失真,尤其是在人物手部区域。长视频生成:MimicMotion采用渐进式潜在融合技术,允许系统在生成长视频时保持高时间连贯性。该技术通过在视频段之间融合潜在特征,有效避免了闪烁和不连贯现象。资源消耗控制:在生成视频时,MimicMotion优化算法以确保资源消耗保持在合理范围内。即使在生成较长视频时,也能有效地管理计算资源,避免过高的成本。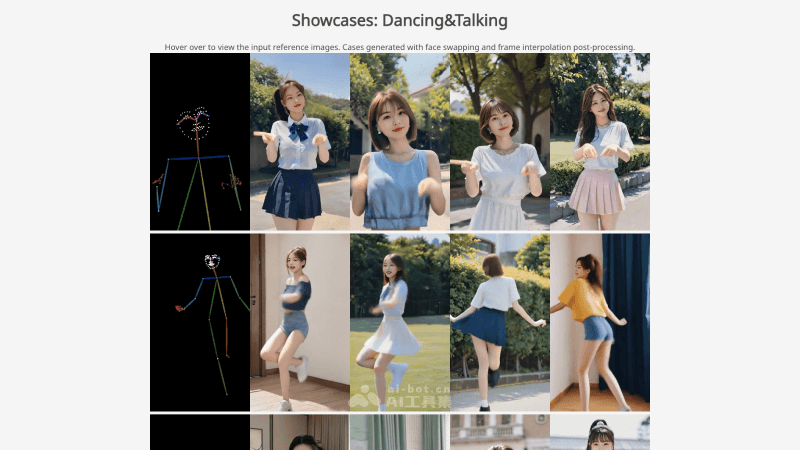
MimicMotion的官网入口
官方项目主页:https://tencent.github.io/MimicMotion/GitHub源代码库:https://github.com/Tencent/MimicMotionarXiv技术论文:https://arxiv.org/abs/2406.19680MimicMotion的技术原理
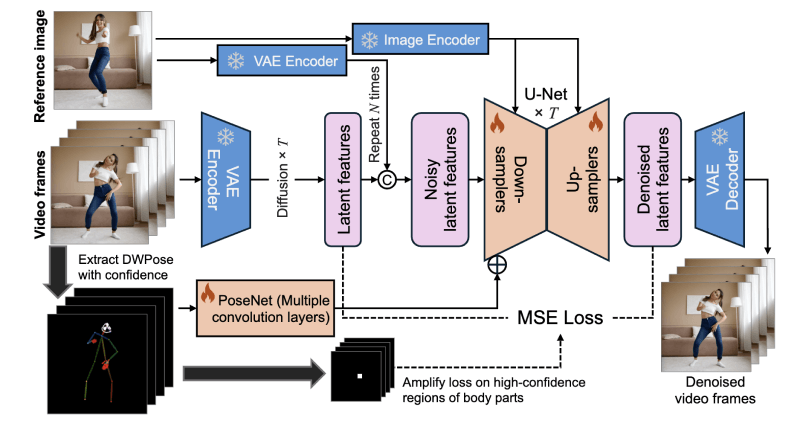 姿态引导的视频生成:MimicMotion利用用户提供的姿态序列作为输入条件,引导视频内容的生成,允许模型根据姿态的变化合成相应的动作。置信度感知的姿态指导:框架引入了置信度的概念,通过分析姿态估计模型提供的置信度分数,对姿态序列中的每个关键点进行加权。这样,模型可以更加信赖那些置信度高的关键点,减少不准确姿态估计对生成结果的影响。区域损失放大:特别针对手部等容易失真的区域,MimicMotion通过提高这些区域在损失函数中的权重,增强模型对这些区域的训练,从而提高生成视频的手部细节质量。潜在扩散模型:MimicMotion使用潜在扩散模型来提高生成效率和质量,模型通过在低维潜在空间中进行扩散过程,而不是直接在像素空间操作,从而减少了计算成本。渐进式潜在融合:为了生成长视频,MimicMotion采用了一种渐进式潜在融合策略。在视频段之间,通过逐步融合重叠帧的潜在特征,实现了视频段之间的平滑过渡,避免了生成长视频时可能出现的闪烁和不连贯现象。预训练模型的利用:MimicMotion基于一个预训练的视频生成模型(如Stable Video Diffusion, SVD),减少了从头开始训练模型所需的数据量和计算资源。U-Net和PoseNet的结构:MimicMotion的模型结构包括一个用于空间时间交互的U-Net和一个用于提取姿态序列特征的PoseNet。这些网络结构共同工作,以实现高质量的视频生成。跨帧平滑性:MimicMotion在生成过程中考虑了帧之间的时间关系,确保了视频帧之间的连贯性和平滑性。
姿态引导的视频生成:MimicMotion利用用户提供的姿态序列作为输入条件,引导视频内容的生成,允许模型根据姿态的变化合成相应的动作。置信度感知的姿态指导:框架引入了置信度的概念,通过分析姿态估计模型提供的置信度分数,对姿态序列中的每个关键点进行加权。这样,模型可以更加信赖那些置信度高的关键点,减少不准确姿态估计对生成结果的影响。区域损失放大:特别针对手部等容易失真的区域,MimicMotion通过提高这些区域在损失函数中的权重,增强模型对这些区域的训练,从而提高生成视频的手部细节质量。潜在扩散模型:MimicMotion使用潜在扩散模型来提高生成效率和质量,模型通过在低维潜在空间中进行扩散过程,而不是直接在像素空间操作,从而减少了计算成本。渐进式潜在融合:为了生成长视频,MimicMotion采用了一种渐进式潜在融合策略。在视频段之间,通过逐步融合重叠帧的潜在特征,实现了视频段之间的平滑过渡,避免了生成长视频时可能出现的闪烁和不连贯现象。预训练模型的利用:MimicMotion基于一个预训练的视频生成模型(如Stable Video Diffusion, SVD),减少了从头开始训练模型所需的数据量和计算资源。U-Net和PoseNet的结构:MimicMotion的模型结构包括一个用于空间时间交互的U-Net和一个用于提取姿态序列特征的PoseNet。这些网络结构共同工作,以实现高质量的视频生成。跨帧平滑性:MimicMotion在生成过程中考虑了帧之间的时间关系,确保了视频帧之间的连贯性和平滑性。 相关推荐