AniTalker-上海交大开源的对口型说话视频生成框架
文章来源:智汇AI 发布时间:2025-08-06
AniTalker是由来自上海交大X-LANCE实验室和思必驰AISpeech的研究人员推出的AI对口型说话视频生成框架,能够将单张静态人像和输入的音频转换成栩
暂无访问AniTalker是什么
AniTalker是由来自上海交大X-LANCE实验室和思必驰AISpeech的研究人员推出的AI对口型说话视频生成框架,能够将单张静态人像和输入的音频转换成栩栩如生的动画对话视频。该框架通过自监督学习策略捕捉面部的复杂动态,包括微妙的表情和头部动作。AniTalker利用通用运动表示和身份解耦技术,减少了对标记数据的依赖,同时结合扩散模型和方差适配器,生成多样化和可控制的面部动画,可实现类似阿里EMO和腾讯AniPortrait的效果。
AniTalker的主要功能
静态肖像动画化:AniTalker能够将任何单张人脸肖像转换成动态视频,其中人物能够进行说话和表情变化。音频同步:该框架能够将输入的音频与人物的唇动和语音节奏同步,实现自然的对话效果。面部动态捕捉:不仅仅是唇动同步,AniTalker还能模拟一系列复杂的面部表情和微妙的肌肉运动。多样化动画生成:利用扩散模型,AniTalker能够生成具有随机变化的多样化面部动画,增加了生成内容的自然性和不可预测性。实时面部动画控制:用户可以通过控制信号实时指导动画的生成,包括但不限于头部姿势、面部表情和眼睛运动。语音驱动的动画生成:框架支持直接使用语音信号来生成动画,无需额外的视频输入。长视频连续生成:AniTalker能够连续生成长时间的动画视频,适用于长时间的对话或演讲场景。
AniTalker的官网入口
官方项目主页:https://x-lance.github.io/AniTalker/GitHub源码库:https://github.com/X-LANCE/AniTalkerarXiv研究论文:https://arxiv.org/abs/2405.03121AniTalker的工作原理
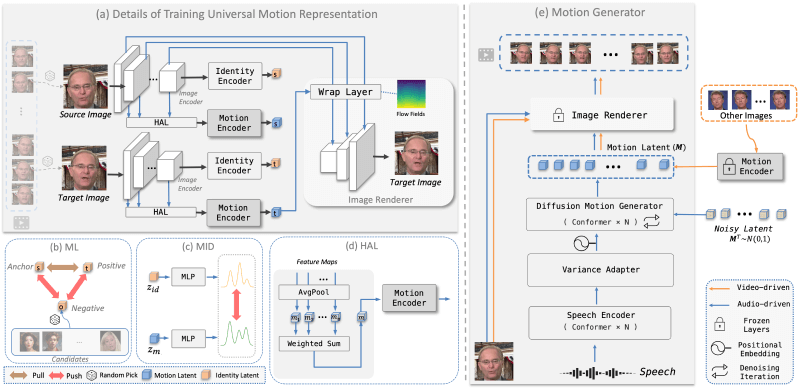 运动表示学习:AniTalker使用自监督学习方法来训练一个能够捕捉面部动态的通用运动编码器。这个过程涉及到从视频中选取源图像和目标图像,并通过重建目标图像来学习运动信息。身份与运动解耦:为了确保运动表示不包含身份特定的信息,AniTalker采用了度量学习和互信息最小化技术。度量学习帮助模型区分不同个体的身份信息,而互信息最小化确保运动编码器专注于捕捉运动而非身份特征。分层聚合层(HAL):引入HAL( Hierarchical Aggregation Layer)来增强运动编码器对不同尺度运动变化的理解能力。HAL通过平均池化层和加权和层整合来自图像编码器不同阶段的信息。运动生成:在训练好运动编码器之后,AniTalker可以基于用户控制的驱动信号生成运动表示。这包括视频驱动和语音驱动的管道。视频驱动管道:使用驱动演讲者的视频序列来为源图像生成动画,从而准确复制驱动姿势和面部表情。语音驱动管道:与视频驱动不同,语音驱动方法根据语音信号或其他控制信号来生成视频,与输入的音频同步。扩散模型和方差适配器:在语音驱动方法中,AniTalker使用扩散模型来生成运动潜在序列,并使用方差适配器引入属性操作,从而产生多样化和可控的面部动画。渲染模块:最后,使用图像渲染器根据生成的运动潜在序列逐帧渲染最终的动画视频。训练和优化:AniTalker的训练过程包括多个损失函数,如重建损失、感知损失、对抗损失、互信息损失和身份度量学习损失,以优化模型性能。控制属性特征:AniTalker允许用户控制头部姿态和相机参数,如头部位置和面部大小,以生成具有特定属性的动画。
运动表示学习:AniTalker使用自监督学习方法来训练一个能够捕捉面部动态的通用运动编码器。这个过程涉及到从视频中选取源图像和目标图像,并通过重建目标图像来学习运动信息。身份与运动解耦:为了确保运动表示不包含身份特定的信息,AniTalker采用了度量学习和互信息最小化技术。度量学习帮助模型区分不同个体的身份信息,而互信息最小化确保运动编码器专注于捕捉运动而非身份特征。分层聚合层(HAL):引入HAL( Hierarchical Aggregation Layer)来增强运动编码器对不同尺度运动变化的理解能力。HAL通过平均池化层和加权和层整合来自图像编码器不同阶段的信息。运动生成:在训练好运动编码器之后,AniTalker可以基于用户控制的驱动信号生成运动表示。这包括视频驱动和语音驱动的管道。视频驱动管道:使用驱动演讲者的视频序列来为源图像生成动画,从而准确复制驱动姿势和面部表情。语音驱动管道:与视频驱动不同,语音驱动方法根据语音信号或其他控制信号来生成视频,与输入的音频同步。扩散模型和方差适配器:在语音驱动方法中,AniTalker使用扩散模型来生成运动潜在序列,并使用方差适配器引入属性操作,从而产生多样化和可控的面部动画。渲染模块:最后,使用图像渲染器根据生成的运动潜在序列逐帧渲染最终的动画视频。训练和优化:AniTalker的训练过程包括多个损失函数,如重建损失、感知损失、对抗损失、互信息损失和身份度量学习损失,以优化模型性能。控制属性特征:AniTalker允许用户控制头部姿态和相机参数,如头部位置和面部大小,以生成具有特定属性的动画。AniTalker的应用场景
虚拟助手和客服:AniTalker可以生成逼真的虚拟面孔,用于虚拟助手或在线客服,提供更加自然和亲切的交互体验。电影和视频制作:在电影后期制作中,AniTalker可以用来生成或编辑演员的面部表情和动作,尤其是在捕捉原始表演时无法实现的场景。游戏开发:游戏开发者可以利用AniTalker为游戏角色创建逼真的面部动画,增强游戏的沉浸感和角色的表现力。视频会议:在视频会议中,AniTalker可以为参与者生成虚拟面孔,尤其是在需要保护隐私或增加趣味性的场合。社交媒体:用户可以利用AniTalker创建个性化的虚拟形象,在社交媒体上进行交流和分享。新闻播报:AniTalker可以生成虚拟新闻主播,用于自动化新闻播报,尤其是在需要多语言播报时。广告和营销:企业可以利用AniTalker生成吸引人的虚拟角色,用于广告宣传或品牌代言。相关推荐