DesignEdit-微软等开源的AI图像分层处理编辑框架
文章来源:智汇AI 发布时间:2025-08-06
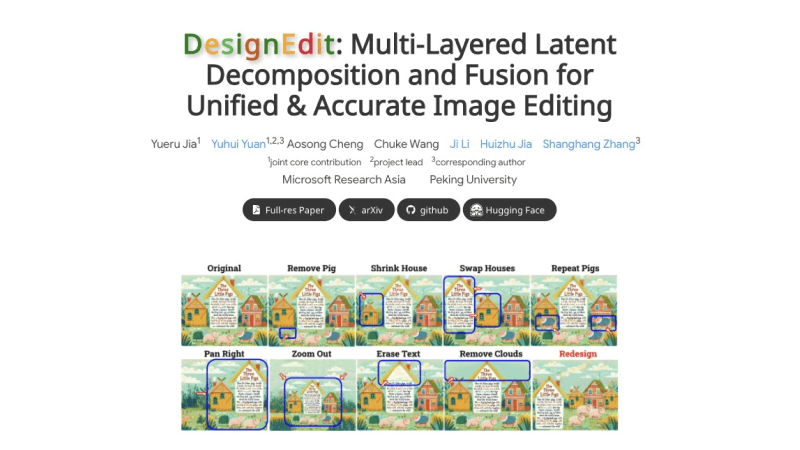
DesignEdit是由微软亚洲研究院和北京大学的研究团队共同开发的一个AI图像编辑框架,引入了设计领域的图层概念,采用多层潜在分解和融合的技术,实现了无需额外
暂无访问DesignEdit是什么
DesignEdit是由来自微软亚洲研究院和北京大学的研究人员共同开发的一个AI图像编辑框架,引入了设计领域的图层概念,采用多层潜在分解和融合的技术,实现了无需额外训练即可进行精确的空间感知图像编辑和处理。通过关键掩码自注意力机制和伪影抑制方案,DesignEdit能够灵活处理图像中的各个对象,并执行诸如移动、调整大小、移除等复杂操作。
DesignEdit的官网入口
官方项目主页:https://design-edit.github.io/arXiv研究论文:https://arxiv.org/abs/2403.14487GitHub源码库:https://github.com/design-edit/DesignEditHugging Face Demo:https://huggingface.co/spaces/YuhuiYuan/DesignEditDesignEdit的主要功能
对象移除:DesignEdit可以从图像中精确移除指定的对象,无论是单个还是多个对象。通过多层潜在分解,框架能够独立处理每个对象,并在移除后自然地修复背景。对象移动:框架允许用户将图像中的一个或多个对象移动到新的位置。通过指令引导的潜在融合,对象可以在画布上重新定位,同时保持与周围环境的和谐。对象调整大小和翻转:DesignEdit能够对图像中的对象进行缩放和翻转操作,用户可以改变对象的尺寸或方向,而不会影响图像的其他部分。相机平移和缩放:模拟相机视角的变化,DesignEdit可以在图像中实现平移和缩放效果,允许用户调整图像的构图,就像通过相机镜头观察时移动或调整焦距一样。跨图像组合:DesignEdit支持将来自不同图像的元素组合在一起,创建全新的图像。这项功能特别适合于创意工作,可以结合多个图像的元素来创作新的视觉内容。设计图像编辑:特别针对设计图像/海报,DesignEdit能够处理文本、装饰和其他设计元素的编辑任务。它能够理解设计图像的特殊需求,如排版和样式的调整,提供更加精细的编辑控制。DesignEdit的工作原理
DesignEdit的工作原理基于两个核心子任务的结合:多层潜在分解(Multi-Layered Latent Decomposition)和多层潜在融合(Multi-Layered Latent Fusion)。
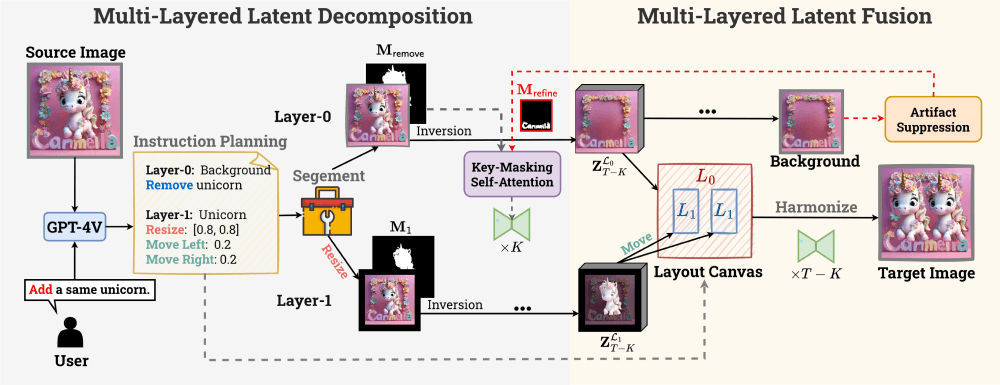 多层潜在分解:概念:DesignEdit将源图像的潜在表示(latent representation)分割成多个层次,每个层次代表图像中的不同对象或背景部分。关键掩码自注意力:为了在不破坏图像其他区域的情况下编辑特定区域,DesignEdit采用了一种特殊的自注意力机制,称为关键掩码(key-masking)自注意力。这种机制允许模型在处理图像时忽略或修改掩码区域内的像素,同时保留周围区域的上下文信息。背景修复:在移除对象后,DesignEdit利用自注意力机制中的内在修复能力来填补背景中的空白区域,确保图像的连贯性和自然过渡。多层潜在融合:指令引导的融合:在分解步骤之后,DesignEdit根据用户的编辑指令,将编辑后的多个潜在表示层融合到一个新的画布上。这个过程是按照特定的图层顺序和用户指定的布局安排进行的。伪影抑制:为了提高编辑质量,DesignEdit在潜在空间中引入了伪影抑制方案。这个方案有助于减少编辑过程中可能出现的视觉瑕疵,使图像看起来更加自然和真实。和谐化处理:在融合过程中,DesignEdit通过额外的去噪步骤来协调融合后的多层潜在表示,进一步优化图像边缘的整合和界面的平滑过渡。
多层潜在分解:概念:DesignEdit将源图像的潜在表示(latent representation)分割成多个层次,每个层次代表图像中的不同对象或背景部分。关键掩码自注意力:为了在不破坏图像其他区域的情况下编辑特定区域,DesignEdit采用了一种特殊的自注意力机制,称为关键掩码(key-masking)自注意力。这种机制允许模型在处理图像时忽略或修改掩码区域内的像素,同时保留周围区域的上下文信息。背景修复:在移除对象后,DesignEdit利用自注意力机制中的内在修复能力来填补背景中的空白区域,确保图像的连贯性和自然过渡。多层潜在融合:指令引导的融合:在分解步骤之后,DesignEdit根据用户的编辑指令,将编辑后的多个潜在表示层融合到一个新的画布上。这个过程是按照特定的图层顺序和用户指定的布局安排进行的。伪影抑制:为了提高编辑质量,DesignEdit在潜在空间中引入了伪影抑制方案。这个方案有助于减少编辑过程中可能出现的视觉瑕疵,使图像看起来更加自然和真实。和谐化处理:在融合过程中,DesignEdit通过额外的去噪步骤来协调融合后的多层潜在表示,进一步优化图像边缘的整合和界面的平滑过渡。整个编辑过程是免训练的,意味着不需要针对特定任务进行额外的训练或微调。DesignEdit利用先进的深度学习模型,如GPT-4V,来辅助生成精确的编辑指令和布局安排,从而实现高效、准确的图像编辑。
相关推荐