IP-Adapter-腾讯开源的文本到图像扩散模型适配器
文章来源:智汇AI 发布时间:2025-08-07
IP-Adapter(Image Prompt Adapter)是一种专门为预训练的文本到图像扩散模型(如Stable Diffusion)设计的适配器,目的是
暂无访问IP-Adapter是什么
IP-Adapter(Image Prompt Adapter)是一种专门为预训练的文本到图像扩散模型(如Stable Diffusion)设计的适配器,目的是让文生图模型能够利用图像提示(image prompt)来生成图像。该方法是由腾讯AI实验室的研究人员提出的,旨在解决仅使用文本提示(text prompt)生成理想图像时的复杂性和挑战。
在传统的文本到图像扩散模型中,用户需要通过编写文本提示来指导模型生成图像,这往往需要复杂的提示工程。而IP-Adapter通过引入图像提示,使得模型能够直接理解图像内容,从而更有效地生成与用户意图相符的图像。这种方法的核心在于它采用了一种解耦的交叉注意力机制,这种机制将文本特征和图像特征的处理分开,使得模型能够更好地理解和利用图像信息。
IP-Adapter的官网入口
官方项目主页:https://ip-adapter.github.io/GitHub代码库:https://github.com/tencent-ailab/IP-AdapterArxiv研究论文:https://arxiv.org/abs/2308.06721Hugging Face 模型地址:https://huggingface.co/h94/IP-AdapterGoogle Colab Demo 地址:https://colab.research.google.com/github/tencent-ailab/IP-Adapter/blob/main/ip_adapter_demo.ipynbIP-Adapter-FaceID Demo:https://huggingface.co/spaces/multimodalart/Ip-Adapter-FaceID
IP-Adapter的功能特色
图像提示集成:IP-Adapter允许模型接收图像作为输入,与文本提示一起,指导图像生成过程。这种方法利用了图像的丰富信息,使得生成的图像更加精确地反映用户的意图。轻量级适配器:尽管IP-Adapter的功能强大,但其参数量相对较小(约22M参数),在计算资源上更加高效,易于部署和使用。泛化能力:IP-Adapter在训练后可以轻松地应用于其他基于相同基础模型微调的自定义模型,可以在不同的应用场景中灵活使用。多模态生成:IP-Adapter支持同时使用文本提示和图像提示进行图像生成,这为用户提供了更多的创作自由度,可以生成更加丰富和多样化的图像内容。结构控制兼容性:IP-Adapter与现有的结构控制工具(如ControlNet)兼容,允许用户在图像生成过程中加入额外的结构条件,如用户绘制的草图、深度图、语义分割图等,以实现更精细的图像控制。无需微调:IP-Adapter的设计避免了对原始扩散模型的微调,这意味着用户可以直接使用预训练模型,而无需进行耗时的微调过程。图像到图像和修复:IP-Adapter不仅支持文本到图像的生成,还可以用于图像到图像的转换和图像修复任务,通过替换文本提示为图像提示来实现。IP-Adapter的工作原理
IP-Adapter的工作原理基于解耦的交叉注意力机制,这一机制允许模型同时处理文本和图像信息,而不会相互干扰。
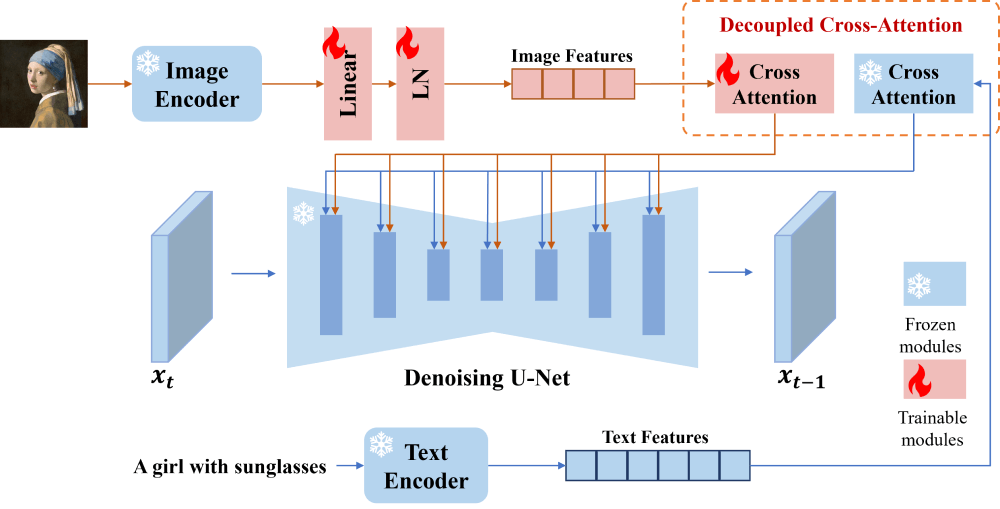
以下是IP-Adapter工作原理的详细步骤:
图像编码:首先,IP-Adapter使用预训练的CLIP(Contrastive Language-Image Pre-training)图像编码器来提取图像提示的特征。CLIP模型通过对比学习在大量图像和文本对上训练,能够理解图像内容并生成与图像相关的文本描述。在IP-Adapter中,CLIP编码器被用来将图像转换为一系列特征向量。特征投影:为了将图像特征与文本特征的维度对齐,IP-Adapter包含一个小型的可训练投影网络,该网络将CLIP编码器的全局图像嵌入转换为与文本特征相同维度的特征序列。解耦的交叉注意力:在预训练的文本到图像扩散模型(如Stable Diffusion)中,文本特征通过交叉注意力层与模型的内部状态进行交互。IP-Adapter在每个交叉注意力层中添加了一个新的层,专门用于处理图像特征。这样,文本特征和图像特征可以分别通过各自的交叉注意力层进行处理,避免了直接合并可能导致的信息损失。训练过程:在训练阶段,IP-Adapter只优化新添加的交叉注意力层的参数,而保持原始的扩散模型参数不变。这样,IP-Adapter可以在不改变原始模型结构的情况下,学习如何将图像特征融入到图像生成过程中。生成过程:在生成图像时,IP-Adapter将文本提示和图像提示的特征输入到模型中。模型首先通过文本交叉注意力层处理文本特征,然后通过图像交叉注意力层处理图像特征。最后,这些特征被合并并输入到扩散模型的去噪网络中,逐步生成图像。结构控制:IP-Adapter与现有的结构控制工具(如ControlNet)兼容,这意味着用户可以在生成过程中添加额外的结构条件,如草图、深度图等,以实现更精细的图像控制。相关推荐