研究显示:AI解6x6数独都费劲,解释决策时还答非所问
文章来源:智汇AI 发布时间:2025-08-08
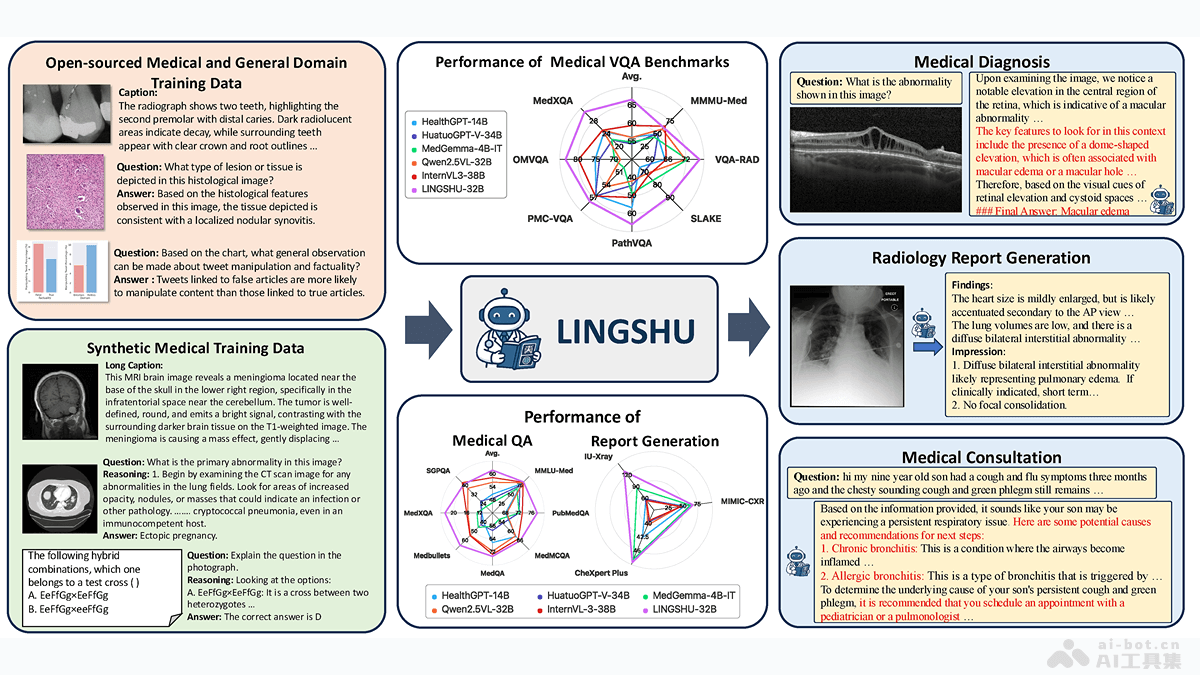
科罗拉多大学研究发现,大型语言模型(LLM)在解决数独等逻辑问题时表现不佳,难以准确解释决策过程。研究指出,这种解释能力的缺失可能影响AI在驾驶、商业决策等领域的可靠性。
暂无访问智汇AI8月7日消息,科罗拉多大学博尔德分校的研究人员在《计算语言学协会研究发现》上发表了一篇论文,揭示了大型语言模型(LLM)在解决数独问题时的局限性,尤其是其在解释决策过程中的不足。
研究人员发现,即使是相对简单的6×6数独,大多数大型语言模型在没有外部辅助工具的情况下也难以解决。这一现象反映出LLM在逻辑推理方面的短板。数独的本质并非数学运算,而是一种符号逻辑游戏,需要从整体出发,找到符合逻辑的解题顺序,而LLM往往会按照训练数据中类似情况的模式,逐个填充空缺,这种逐个推理的方式难以应对数独的复杂逻辑。
而且,当研究人员要求这些模型展示解题过程时,结果令人失望。大多数情况下,模型无法准确、透明地解释其决策过程。有时它们会给出看似合理的解释,但这些解释并不符合实际的解题步骤;有时甚至会给出与问题完全无关的回答,例如在一次测试中,OpenAI的o4推理模型在被问及数独问题时,突然开始谈论丹佛的天气预报。
科罗拉多大学计算机科学教授阿舒托什・特里维迪(AshutoshTrivedi)指出,如果生成式AI工具不能准确、透明地解释其决策过程,那么随着我们越来越多地将生活和决策权交给这些工具,就必须保持谨慎。他强调:“我们希望这些解释能够透明地反映AI做出决策的原因,而不是AI为了迎合人类而提供人类可能喜欢的解释。”
智汇AI注意到,这种解释能力的缺失并非仅在数独问题上体现。研究人员还发现,LLM在其他逻辑游戏(如国际象棋和汉诺塔问题)中也存在类似问题。以国际象棋为例,LLM虽然能够找到合理的下一步棋,但往往无法像人类高手那样提前规划多步棋局,甚至有时会违反规则移动棋子,导致局面陷入混乱。
此外,研究人员还指出,解释能力对于AI的应用至关重要。随着AI在驾驶、税务处理、商业决策和重要文件翻译等领域的应用逐渐增加,其解释能力将成为衡量其可靠性的关键因素。特里维迪教授警告说:“如果AI的解释是为了错误的原因而进行的,那么这种解释就非常接近于操纵。我们必须非常谨慎地对待这些解释的透明度。”
相关推荐