Step-Audio-AQAA-StepFun推出的端到端大音频语言模型
文章来源:智汇AI 发布时间:2025-08-12
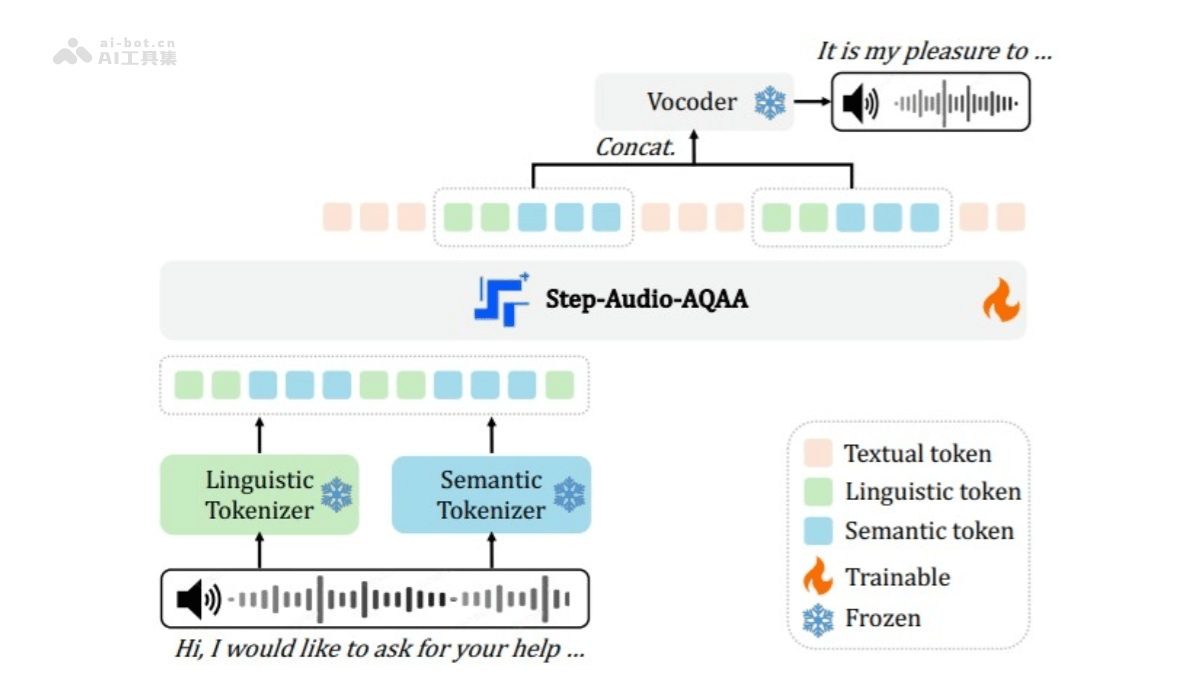
Step-Audio-AQAA 是 StepFun 团队推出的端到端大型音频语言模型,专门用于音频查询-音频回答(AQAA)任务。能直接处理音频输入生成自然、准
暂无访问Step-Audio-AQAA是什么
Step-Audio-AQAA 是 StepFun 团队推出的端到端大型音频语言模型,专门用于音频查询-音频回答(AQAA)任务。能直接处理音频输入生成自然、准确的语音回答,无需依赖传统的自动语音识别(ASR)和文本到语音(TTS)模块,简化了系统架构并消除了级联错误。Step-Audio-AQAA 的训练过程包括多模态预训练、监督微调(SFT)、直接偏好优化(DPO)以及模型合并。通过这些方法,模型在语音情感控制、角色扮演、逻辑推理等复杂任务中表现出色。在 StepEval-Audio-360 基准测试中,Step-Audio-AQAA 在多个关键维度上超越了现有的 LALM 模型,展现了在端到端语音交互中的强大潜力。
Step-Audio-AQAA的主要功能
直接处理音频输入:能直接从原始音频输入生成语音回答,无需依赖传统的自动语音识别(ASR)和文本到语音(TTS)模块。相关推荐