SRPO-腾讯混元推出的文生图模型
文章来源:智汇AI 发布时间:2025-09-15
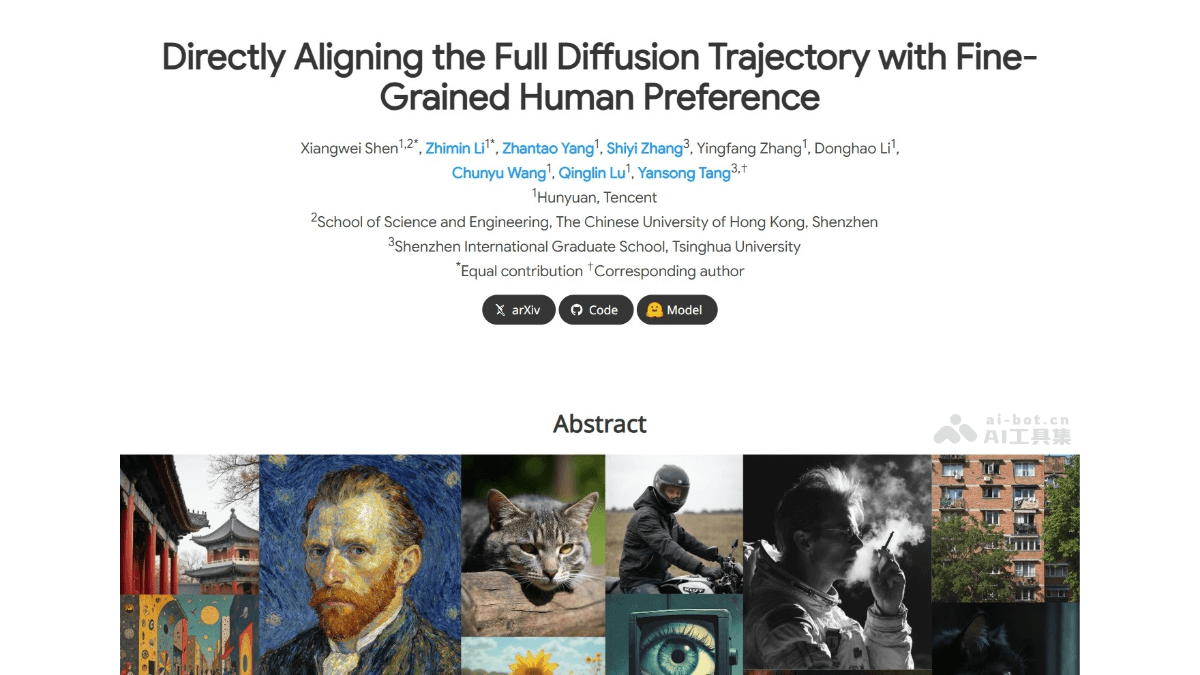
SRPO(Semantic Relative Preference Optimization)是腾讯混元推出的文本到图像生成模型,通过将奖励信号设计为文本条件信
暂无访问SRPO是什么
SRPO(Semantic Relative Preference Optimization)是腾讯混元推出的文本到图像生成模型,通过将奖励信号设计为文本条件信号,实现对奖励的在线调整,减少对离线奖励微调的依赖。SRPO引入Direct-Align技术,通过预定义噪声先验直接从任何时间步恢复原始图像,避免在后期时间步的过度优化问题。在FLUX.1.dev模型上的实验表明,SRPO能显著提升生成图像的人类评估真实感和审美质量,且训练效率极高,仅需10分钟即可完成优化。
SRPO的主要功能
提升图像生成质量:通过优化扩散模型,使生成的图像在真实感、细节丰富度和审美质量上显著提升。相关推荐