FunAudio-ASR-阿里达摩院推出的端到端语音识别模型
文章来源:智汇AI 发布时间:2025-09-16
FunAudio-ASR 是阿里巴巴达摩院推出的端到端语音识别大模型,专为解决企业落地中的关键问题设计。通过创新的 Context 增强模块,有效优化了“幻觉”
暂无访问FunAudio-ASR是什么
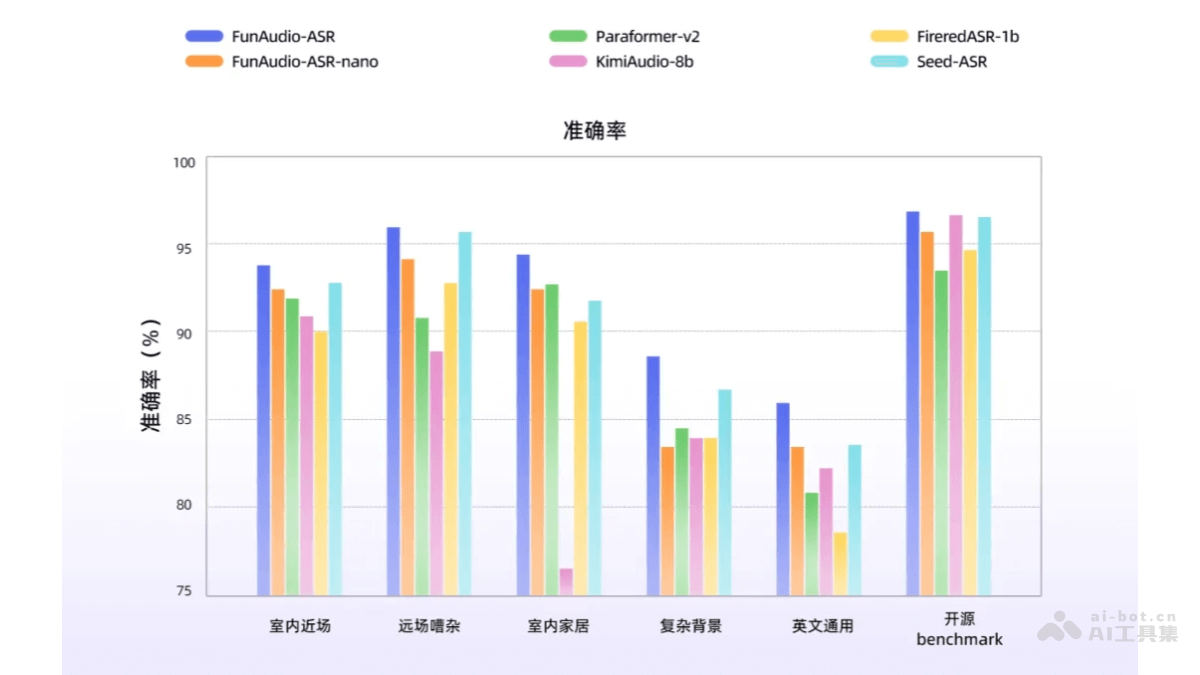
FunAudio-ASR 是阿里巴巴达摩院推出的端到端语音识别大模型,专为解决企业落地中的关键问题设计。通过创新的 Context 增强模块,有效优化了“幻觉”和“串语种”等问题。模块利用 CTC 解码器快速生成第一遍转写文本,将其作为上下文信息输入 LLM,显著提升了识别的准确性和稳定性。FunAudio-ASR 在远场、嘈杂背景等复杂场景下表现出色,轻量化版本 FunAudio-ASR-nano 适合资源受限的部署环境。模型引入了 RAG 机制,通过动态检索和精准注入定制词,大幅提升了个性化定制能力。
FunAudio-ASR的主要功能
高精度语音识别:通过创新的 Context 增强模块,显著优化了“幻觉”“串语种”等工业场景中的关键问题,提升了识别准确率。相关推荐