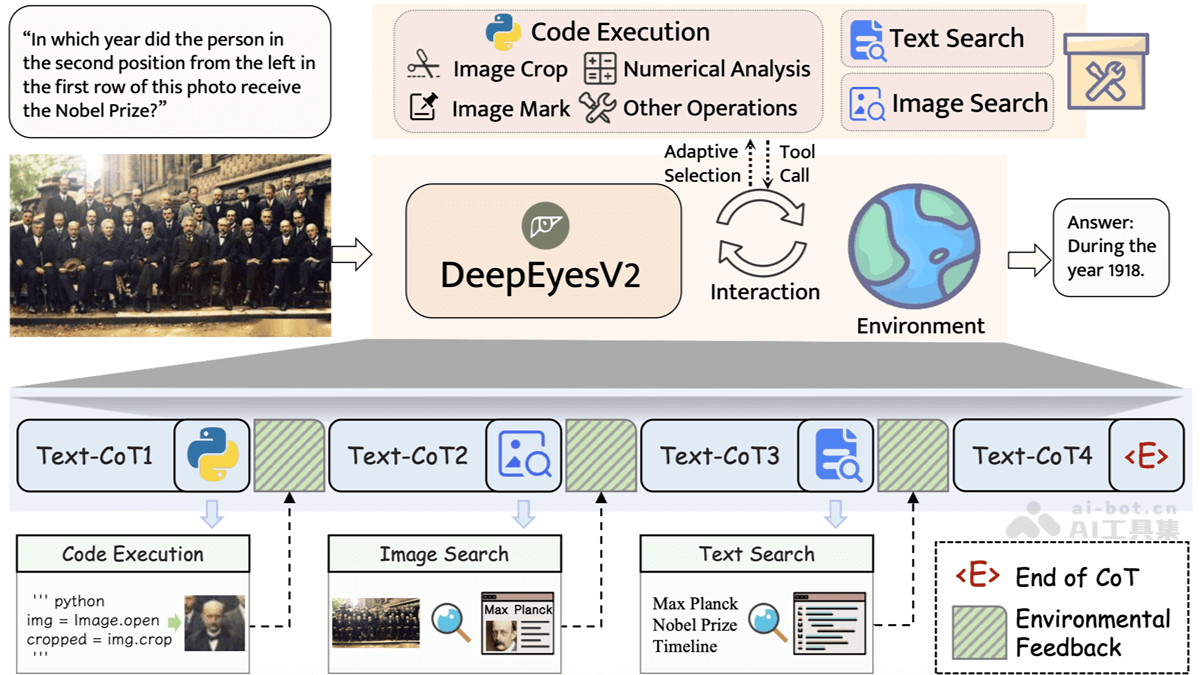
Omnilingual ASR-Meta AI推出的自动语音识别系统
文章来源:智汇AI 发布时间:2025-11-12
Omnilingual ASR 是 Meta AI 推出的自动语音识别系统,支持超过1600种语言,包括500种低资源语言。Omnilingual ASR通过扩
暂无访问Omnilingual ASR是什么
Omnilingual ASR 是 Meta AI 推出的自动语音识别系统,支持超过1600种语言,包括500种低资源语言。Omnilingual ASR通过扩展 wav2vec 2.0 编码器到70亿参数,引入两种解码器,实现卓越的性能,78%的语言字符错误率低于10%。Omnilingual ASR 框架社区驱动,用户只需提供少量样本能扩展到新语言。同时,Meta 开源了 Omnilingual ASR Corpus 数据集和 Omnilingual wav2vec 2.0全新的自监督式大规模多语言语音表示模型,助力全球语音技术发展,推动语言平等与文化交流。
Omnilingual ASR的主要功能
多语言语音转录:Omnilingual ASR 能将超过 1600 种语言的语音转换为文本,包括许多低资源语言和从未被 AI 转录过的语言。社区扩展能力:用户能通过提供少量音频和文本样本,将模型扩展到新的语言,无需大量训练数据或专业知识。高性能与低错误率:在 78% 的语言中,字符错误率(CER)低于 10%,达到行业领先水平。多种模型选择:提供从轻量级 300M 到强大的 7B 模型,适用于不同设备和用例。开源与数据共享:开源 Omnilingual wav2vec 2.0 模型和 Omnilingual ASR Corpus 数据集,支持全球开发者和研究者进行进一步开发和研究。Omnilingual ASR的技术原理
wav2vec 2.0 扩展:将 wav2vec 2.0 编码器扩展到 70 亿参数,能从原始语音数据中提取丰富的多语言语义表征。双解码器架构:使用两种解码器,传统的连接主义时间分类(CTC)和基于 Transformer 的解码器,后者借鉴大型语言模型(LLM)的技术,显著提升长尾语言的性能。上下文学习能力:受 LLM 启发,模型能通过少量上下文样本快速适应新语言,无需大规模训练数据或复杂调整。大规模多语言数据集:训练语料库整合公开数据集和社区提供的语音记录,覆盖大量低资源语言,为模型提供广泛的语言基础。Omnilingual ASR的项目地址
项目官网:https://ai.meta.com/blog/omnilingual-asr-advancing-automatic-speech-recognition/GitHub仓库:https://github.com/facebookresearch/omnilingual-asrHuggingFace模型库:https://huggingface.co/datasets/facebook/omnilingual-asr-corpus技术论文:https://ai.meta.com/research/publications/omnilingual-asr-open-source-multilingual-speech-recognition-for-1600-languages/Omnilingual ASR的应用场景
跨语言交流:帮助不同语言背景的人进行实时语音交流,打破语言障碍,促进国际合作与文化交流。相关推荐