SAM Audio-Meta开源的音频分割模型
文章来源:智汇AI 发布时间:2025-12-19
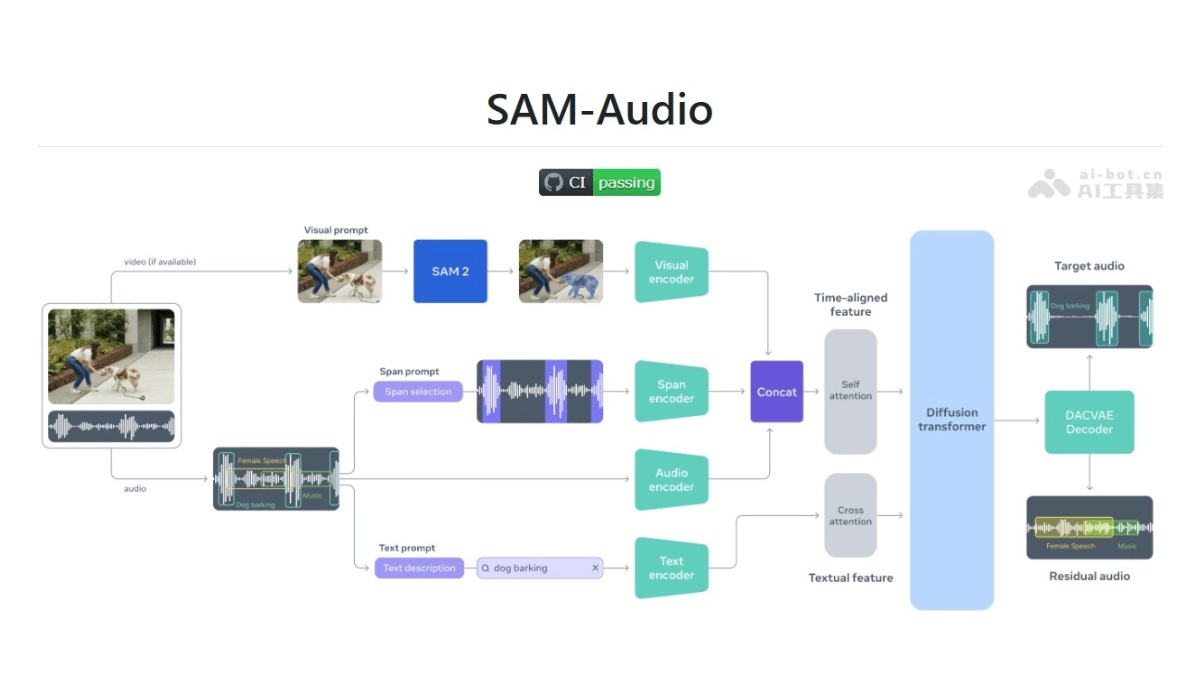
SAM Audio是Meta开源的音频分割模型,能通过文本、视觉和时间片段等多模态提示,从复杂的音频混合中分离出特定的声音。核心技术是Perception En
暂无访问SAM Audio是什么
SAM Audio是Meta开源的音频分割模型,能通过文本、视觉和时间片段等多模态提示,从复杂的音频混合中分离出特定的声音。核心技术是Perception Encoder Audiovisual(PE-AV),基于Meta开源的Perception Encoder模型,能融合视听信息并进行精确的时间标注,实现高精度的音频分离。用户可以通过简单的文本描述(如“吉他声”)、在视频中点击发声物体,或者标记声音出现的时间范围来使用SAM Audio。
SAM Audio的主要功能
多模态提示音频分离:通过文本描述、视觉选择(视频中的对象)或时间片段标记,从复杂音频混合中分离出特定声音。相关推荐


























