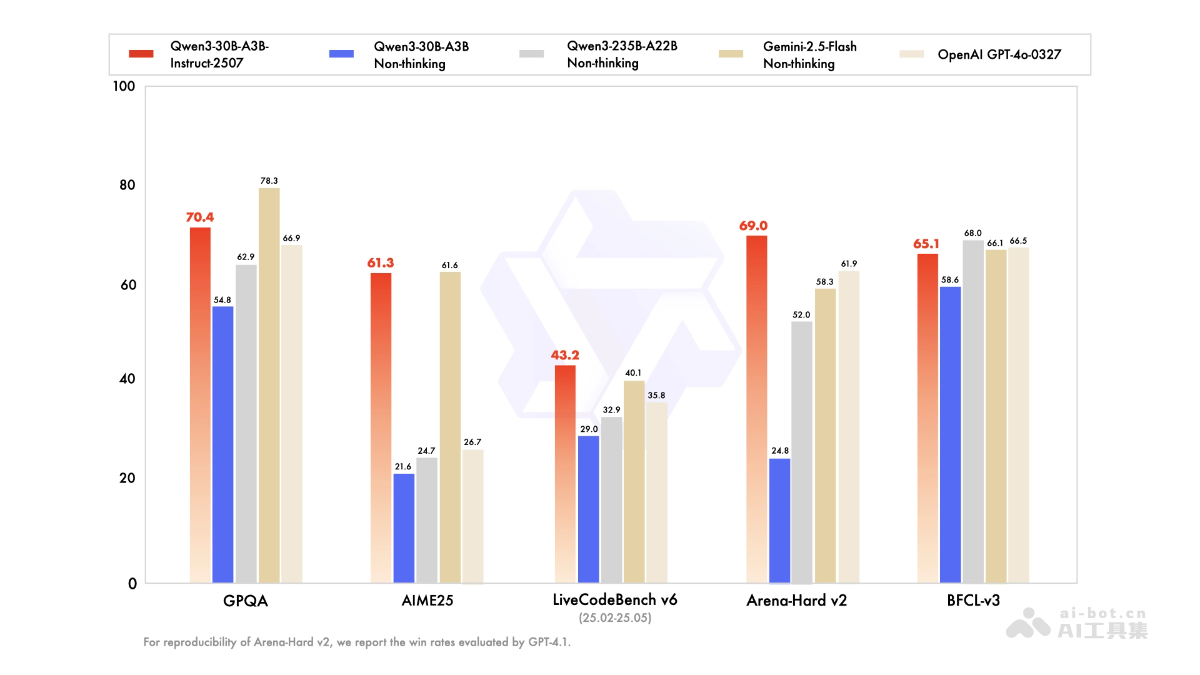
什么是审议对齐(Deliberative-Alignment)
文章来源:智汇AI 发布时间:2025-04-10
审议对齐(Deliberative Alignment)是OpenAI提出的一种新的训练方法,旨在提高大型语言模型的安全性和可靠性。这种方法通过结合基于过程和结果的监督,让模型在产生答案之前明确地通过安全规范进行复杂推理。
暂无访问审议对齐(Deliberative Alignment)是OpenAI在提高AI模型安全性方面的一项重要技术进展。通过直接教授模型安全规范并训练模型在回答之前明确回忆规范并准确地执行推理,审议对齐提高了模型的安全性,同时减少了对人工标注数据的依赖。这种方法在内部和外部的安全基准测试中显示出了显著的效果,为AI模型的安全性训练提供了新的方向。随着o3系列模型的进一步测试和应用,我们可以期待AI技术在安全性和可靠性方面取得更大的进步。
什么是审议对齐
审议对齐(Deliberative Alignment)是OpenAI提出的一种新的训练方法,旨在提高大型语言模型的安全性和可靠性。这种方法通过结合基于过程和结果的监督,直接教授模型安全规范,训练模型在回答之前明确回忆并准确推理这些规范。这种方法使模型能使用链式思考(Chain-of-Thought,CoT)推理来审视用户的提示,识别相关的政策指导,生成更安全的回应。简而言之,审议对齐是一种通过直接教授和推理安全规范来提高AI模型安全性和可靠性的方法。
审议对齐的工作原理
数据生成从一系列与安全类别(例如色情、自残)相关的提示开始。为每个(提示,类别)对编写与该提示的安全类别相关的安全规范,包括有关不允许的内容和风格。通过提示一个没有安全规范知识的推理模型Gbase,并提供相关的安全规范文本,收集(CoT,输出)完成对,这些完成对在思维链(CoT)中引用了我们的政策。筛选使用“裁判”推理模型GRM(也被提示了我们的规范)来选择高质量的完成对。然后从提示中删除规范,得到一系列(提示,CoT,输出)元组。
监督式微调(Supervised Fine-Tuning, SFT),在过滤完成对之后,使用这些数据对Gbase进行监督式微调训练。模型学习通过引用其CoTs中引用的政策来完成提示,以符合规范的方式。在RL阶段,对于与安全相关的提示,我们再次使用我们的“裁判”模型GRM提供额外的奖励信号。模型可以访问我们的安全政策。独特之处在于,它直接教授模型安全规范,在生成响应之前训练模型明确地回忆和准确推理这些规范。通过这种方式,深思熟虑的对齐能提高模型对安全政策的精确遵循,不需要人工编写的思维链或答案。通过同时增加对越狱攻击的鲁棒性并减少过度拒绝率来推动帕累托前沿,改善了分布外的泛化能力。
审议对齐的主要应用
提高模型安全性:审议对齐通过直接教授模型安全规范,并在回答问题之前要求模型明确回忆并执行这些规范,从而提高模型的安全性。例如,在处理潜在的有害请求时,模型能够通过推理识别出这些请求,并根据内置的安全策略拒绝回答。减少过度拒绝(Over-refusal):在提高安全性的同时,审议对齐还解决了模型过度拒绝合法请求的问题。通过审议对齐训练的模型能够更准确地判断请求的性质,在拒绝有害请求的同时,不会过度限制用户的合法查询。提升模型的推理能力:审议对齐不仅提高了模型的安全性,还增强了模型的推理能力。审议对齐能够有效地提升模型在复杂任务中的推理和问题解决能力。适应不同计算资源需求:审议对齐还考虑到了不同用户对计算资源的需求。o3-mini模型提供了可调整的推理时间设置,允许用户根据任务的复杂性和资源限制选择合适的推理级别。支持多语言和非结构化输入:审议对齐训练的模型不仅在英语处理上表现出色,还能够处理其他语言和非结构化输入,如加密信息。这种泛化能力意味着模型可以在更多样化的环境中保持其安全性和有效性。审议对齐面临的挑战
定义和理解“人类意愿”:审议对齐的核心目标是使AI系统的行为与人类的意愿保持一致。然而,人类的意愿是复杂且多变的,不同文化、社会和个体之间存在显著差异。此外,人类的价值观随时间而变化,这使得捕捉和定义一个普遍接受的“人类意愿”变得极其困难。技术实现的复杂性:审议对齐要求AI系统在做出决策前进行复杂的推理过程。这不仅需要AI系统具备高度的推理能力,还需要能够理解和执行安全规范。过度拒绝和误拒绝:在提高安全性的同时,审议对齐可能会导致模型过度拒绝合法请求。此外,模型可能会错误地接受或拒绝某些请求,这会影响用户体验和模型的可靠性。计算资源的需求:审议对齐模型,如o3系列,需要大量的计算资源来执行复杂的推理过程。这不仅增加了成本,还可能限制了模型的可扩展性。安全性和伦理性:审议对齐需要确保AI系统的行为不仅安全,而且符合伦理标准。这要求AI系统能够识别和处理潜在的伦理问题,这是一个复杂且不断发展的领域。对抗性攻击和滥用:审议对齐模型可能会面临对抗性攻击,攻击者可能会尝试操纵模型以产生有害的输出。此外,模型可能会被滥用,用于不当目的。跨学科合作的挑战:审议对齐是一个跨学科的领域,它涉及到计算机科学、伦理学、社会学等多个学科。这要求不同领域的专家能够有效合作,共同解决挑战。审议对齐的发展前景
审议对齐(Deliberative Alignment)技术作为一种新兴的人工智能训练方法,核心目标是保持和扩展人类在未来的代理性,即人类应能够选择自己的未来。随着人工智能技术的发展,审议对齐技术被用于帮助对齐治理和外交政策与人类意愿,现代AI的加入有望显著提升这项技术的效果。在超人类通用人工智能(AGI)的竞争中,未能将这种强大AI的影响与人类意愿对齐可能导致灾难性后果,而成功则可能释放出丰富资源。当前存在一个机会窗口,可以使用审议技术来对齐强大AI的影响与人类意愿。产业界正在探索将智能审议对齐系统纳入强大的机构中,以及如何将这些系统用于AI对齐。这些探索可能实现AI与审议对齐系统之间的共生改进,随着AI能力的提高,对齐的质量也将提高。科技公司在设计审议过程时考虑了“全球可扩展性”,旨在识别最可行的审议设计,以包括和代表全球范围内的参与者,或测试可以促进未来全球公民审议的AI技术。综上所述,审议对齐技术的发展前景广阔,它将在全球治理、AI安全和伦理、以及科技公司的责任和监管中扮演越来越重要的角色。随着技术的不断发展和实验的深入,审议对齐有望成为确保技术发展与人类价值观一致的关键工具。
相关推荐