大模型首次直接理解代码图:不用Agent自动修bug,登顶SWE-Bench开源模型榜单
文章来源:智汇AI 发布时间:2025-06-27
AI 自动修 bug,解决率达 44%!这是全球开源模型的最新最强水平。来自蚂蚁的开源新模型,在 SWE-bench Lite 上超越所有开源方案,性能媲美闭源模型。
暂无访问AI自动修bug,解决率达44%!这是全球开源模型的最新最强水平。
来自蚂蚁的开源新模型,在SWE-benchLite上超越所有开源方案,性能媲美闭源模型。
具体表现如下,在SWE-benchLite上:
所有开源模型方法(OpenWeightModel)中排名第一;
所有开源系统方法(OpenSourceSyestem)中排名第六;
总体排名第14;
优于目前榜单最好开源模型“KGCompass”7.33%。
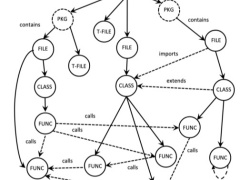
他们首创将仓库代码图模态融入大模型(CodeGraphModel,CGM),让大语言模型能直接理解代码图,更高效修复bug、补全代码。
这彻底摆脱对黑盒模型(如GPT-4或Claude3.7等)和复杂Agent工作流程的依赖,实现更加可控、透明、安全的SE自动化。
而且,CGM完全基于开源模型。要知道,开源模型在SWE-bench上的表现通常不够好,此前几乎所有SOTA级方案都是基于闭源模型实现。而CGM基于Qwen模型,做到了比肩闭源模型的水平。
CGM仅需4步就能快速定位、生成补丁,省去了Agent方案中复杂的编排过程,效率直线up。
让AI真正理解大模型代码库
大模型趋势以来,AI编程迅速崛起,尤其是在写函数这类小任务上的表现出色,比如在HumanEval等基准测试上,许多模型的准确率已经超过90%。
然而真实的软件工程远比”写一个函数“复杂得多。像Bug修复、功能增强这样的任务,通常需要跨文件、跨模块操作,并要求模型理解项目中复杂的结构、依赖关系和类的继承体系。
现在的主流方法通常是使用基于闭源模型的Agent。它们可以模拟人类程序员行为,如观察代码、调用工具、多轮交互等完成任务。
但这类方法也存在几个问题:
行为路径不可控,容易积累推理误差;
依赖GPT-4、Claude等闭源模型,难以私有部署或定制;
工程成本高,效率不高。
与此同时,当前使用开源模型的方案,很难实现SOTA级效果。
为此研究团队提出:能否只用开源模型、不依赖Agent,解决仓库级任务?CGM由此而来。
相关推荐