谷歌Gemini 2.5 Flash-Lite稳定版发布:速度、成本双突破,开发者新利器来了!
文章来源:智汇AI 发布时间:2025-07-24
谷歌又放大招!近日,Gemini 2.5 Flash-Lite稳定版正式上线,官方宣称其是“速度最快、成本最低”的AI模型。这款模型不仅在性能上全面超越前代,更以超低定价直击开发者核心需求,支持百万…
暂无访问最近,谷歌在人工智能领域又扔下一颗“重磅炸弹”——Gemini2.5Flash-Lite稳定版(GA)正式上线!这款被官方称为“速度最快、成本最低”的AI模型,不仅在性能上全面升级,还以超低定价直击开发者痛点,堪称谷歌在AI赛道上的又一次“精准打击”。
谷歌Gemini2.5Flash-Lite稳定版是什么?
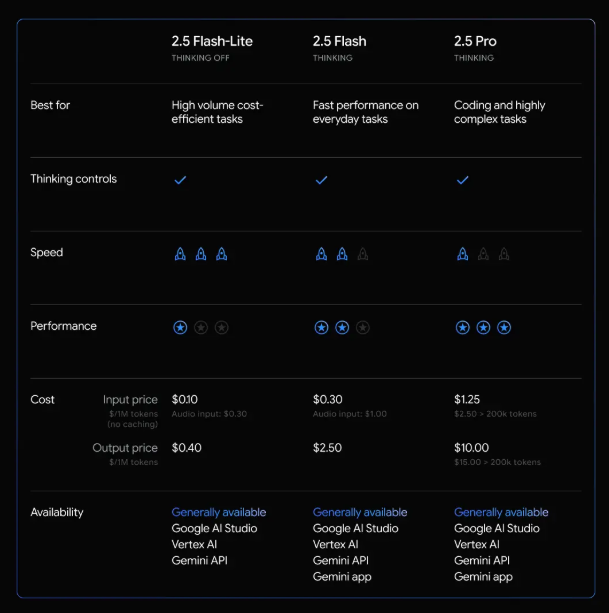
我知道Gemini2.5Flash-Lite。它是美国谷歌公司于2025年6月17日推出的一款轻量级模型,是Gemini2.5混合推理模型中的一种。Gemini2.5Flash-Lite是目前Gemini2.5系列中成本效益最高、推理速度最快的模型,擅长处理高吞吐量、对延迟敏感的任务,如翻译和分类。
该模型支持多模态输入,能原生支持高达100万token的上下文,并具备可控的思考预算,开发者可通过API参数动态控制思考预算,不过其“思考”功能默认处于关闭状态。
此外,它还支持多种原生工具,如与Google搜索的结合、代码执行以及URL上下文等功能。
在定价方面,Gemini2.5Flash-Lite每百万输入token的费用为0.10美元,每百万输出token的费用为0.40美元,音频输入的费用为每百万输入token0.5美元。
在各项基准测试中,它的表现超越了之前的2.0版本,涵盖编码、数学、推理和多模态理解等多个领域。截至2025年6月18日,开发者可通过GoogleAIStudio、VertexAI平台访问Gemini2.5Flash-Lite的预览版本,同时谷歌搜索已部署了定制化版本的该模型以提升服务效率。
体验地址:GoogleAIStudio网页版官网入口
谷歌Gemini2.5Flash-Lite稳定版模型定价价格“卷”出新高度:百万token输入仅1毛钱!
要说Gemini2.5Flash-Lite最吸睛的亮点,定价策略绝对排第一。
输入成本:每百万token仅需0.10美元(约合人民币0.7元),输出成本为0.40美元,直接对标竞争对手GPT-4.1Nano,甚至比部分开源模型更便宜。音频输入降价40%:相比预览版,音频处理费用大幅下调,显然是听到了用户对“降本增效”的强烈呼声。开发者算盘一打就明白:用这款模型跑大规模任务,成本能省下一大截,尤其适合需要处理海量数据或长文本的场景(比如客服、内容生成、数据分析)。
谷歌Gemini2.5Flash-Lite稳定版模型性能1.性能大跃升:100万token上下文,编码推理全搞定
光便宜不够,还得“能打”。Gemini2.5Flash-Lite在多项基准测试中直接超越前代2.0版本,覆盖编码、数学、推理、多模态理解等核心领域。
超长上下文支持:原生支持100万token的上下文窗口,相当于能一口气“读”完一本《哈利·波特》全集,还能精准回答相关问题。可控思考预算(ThinkingBudgets):开发者可以设置模型的“思考时间”,平衡响应速度和结果质量,避免“卡壳”或过度计算。原生工具集成:直接调用Google搜索、代码执行、URL上下文分析等功能,无需额外开发插件,一站式解决复杂需求。举个栗子:
金融行业用它分析财报长文,快速提取关键数据;教育领域用它生成个性化学习计划,结合海量知识库给出建议;游戏开发中用它调试代码,甚至自动生成部分脚本。2.开发者友好:一行代码调用,8月25日预览版将停用
谷歌这次对开发者体验也下了功夫:
调用极简:只需在代码中指定模型为gemini-2.5-flash-lite,即可快速接入,无需复杂配置。兼容性提示:原有预览版别名将在8月25日正式移除,谷歌建议开发者尽快迁移到新版本,避免服务中断。潜台词:别犹豫了,早用早享受!
谷歌的野心:用“性价比”抢占AI应用场景
从Gemini2.5Flash-Lite的定位不难看出,谷歌正试图通过“高性能+低成本”的组合拳,扩大AI模型的落地范围。无论是初创公司、中小企业,还是个人开发者,都能以更低门槛尝试前沿技术,推动AI从“实验室”走向“千行百业”。
未来展望:谷歌透露,后续将优化模型的方言识别、多语言支持能力,并探索医疗、法律等垂直领域的应用。可以预见,这款“平民化”的AI工具,将在更多场景中掀起效率革命。
结语:AI普及化,从“能用”到“好用”
Gemini2.5Flash-Lite的发布,不仅是谷歌技术实力的展示,更是AI行业“降本增效”趋势的缩影。当大模型不再“高冷”,当开发者能以更低成本实现创意,AI的真正价值或许才刚刚开始显现。
对开发者来说:现在就是上手体验的最佳时机,毕竟,谁能拒绝一个“又快又便宜”的AI助手呢?
相关推荐
































