Follow-Your-Click-腾讯等开源的图像到视频模型,可生成局部动画
文章来源:智汇AI 发布时间:2025-08-06
Follow-Your-Click是一个由来自腾讯公司(混元团队)联合清华大学和香港科技大学的研究人员共同研发的图像到视频(Image-to-Video,简称I
暂无访问Follow-Your-Click是什么
Follow-Your-Click是一个由来自腾讯公司(混元团队)联合清华大学和香港科技大学的研究人员共同研发的图像到视频(Image-to-Video,简称I2V)生成模型,允许用户通过简单的点击和简短的动作提示来生成局部图像动画,从而将静态图像转换为动态视频。该模型旨在解决现有的大多数图像到视频方法并不具备局部动画的特性,只能移动整个场景。
Follow-Your-Click的官网入口
官方项目主页:https://follow-your-click.github.io/arXiv研究论文:https://arxiv.org/abs/2403.08268(注:源码和Demo预计4月份上线)GitHub代码库:https://github.com/mayuelala/FollowYourClickFollow-Your-Click的主要功能
简单友好的交互:Follow-Your-Click提供了直观的用户控制界面,用户可以通过简单的点击来指定动画区域,并通过简短的提示词来定义动画类型和动作。局部动画生成:用户可以通过点击图像中的特定区域,使这些区域产生动画效果。即用户可以选择图像的任何部分,并为其添加动态效果,如让物体微笑、摇摆或移动。多对象动画:模型支持对图像中的多个对象同时进行动画处理,允许用户创建更为丰富和复杂的动态场景。简短动作提示:用户只需提供简短的动作描述,模型就能够理解并生成相应的动画效果。简化了动画制作过程,使得用户无需进行复杂的操作或提供冗长的描述。高质量视频生成:模型采用了先进的技术策略,如第一帧遮罩策略和基于光流的运动幅度控制,以确保生成的视频具有高质量和真实感。运动速度控制:模型还允许用户控制动画对象的运动速度,通过精确的控制来满足不同的动画需求。Follow-Your-Click的工作原理
用户交互:用户首先通过点击图像上的特定位置来选择需要动画化的对象区域。这种交互方式简单直观,不需要用户进行复杂的操作或提供详细的描述。接着,用户提供一个简短的动作提示,如“摇动身体”或“微笑”,来指定所选区域应执行的动作。图像分割:为了将用户的点击转换为可以用于动画的区域掩码,框架集成了SAM(Segment Anything)工具。SAM是一个可提示的图像分割工具,能够根据用户的点击生成高质量的对象掩码。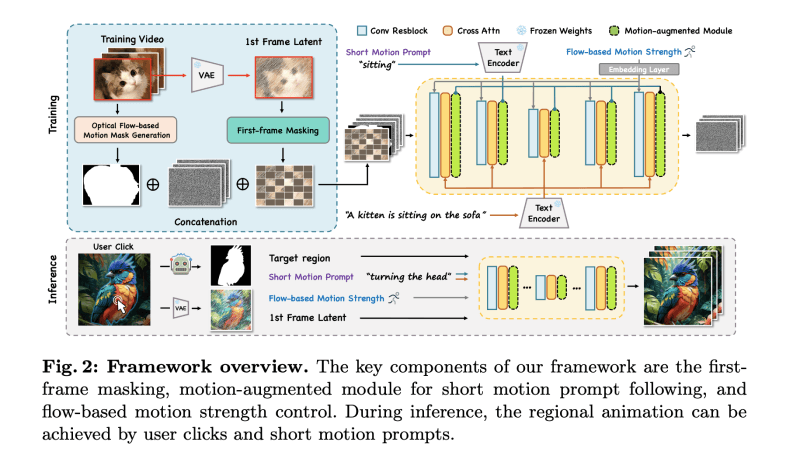 第一帧遮罩策略:为了提高视频生成质量,框架采用了第一帧遮罩策略。在训练过程中,输入图像的潜在表示(latent representation)会被随机遮罩一部分,以增强模型学习时间相关性的能力。这种方法显著提高了生成视频的质量。运动增强模块:为了使模型能够更好地响应简短的动作提示,框架设计了一个运动增强模块。该模块通过一个新的交叉注意力层来增强模型对动作相关词汇的响应。在训练阶段,该模块使用短动作提示进行训练,而在推理阶段,这些提示被输入到运动增强模块和U-Net的交叉注意力模块中。基于光流的运动幅度控制:传统的运动强度控制依赖于调整每秒帧数(FPS)。然而,这种方法不能精确控制单个对象的运动速度。为了准确学习运动速度,框架提出了一种基于光流的运动幅度控制方法。通过计算光流的平均幅度并将其投影到位置嵌入中,可以在所有帧中一致地应用运动强度。视频生成:在推理阶段,用户点击的位置和简短的动作提示被用来生成动画视频。模型结合了用户指定的区域掩码和动作提示,生成了一系列连贯的动画帧,同时保持了输入图像的其余部分静止。
第一帧遮罩策略:为了提高视频生成质量,框架采用了第一帧遮罩策略。在训练过程中,输入图像的潜在表示(latent representation)会被随机遮罩一部分,以增强模型学习时间相关性的能力。这种方法显著提高了生成视频的质量。运动增强模块:为了使模型能够更好地响应简短的动作提示,框架设计了一个运动增强模块。该模块通过一个新的交叉注意力层来增强模型对动作相关词汇的响应。在训练阶段,该模块使用短动作提示进行训练,而在推理阶段,这些提示被输入到运动增强模块和U-Net的交叉注意力模块中。基于光流的运动幅度控制:传统的运动强度控制依赖于调整每秒帧数(FPS)。然而,这种方法不能精确控制单个对象的运动速度。为了准确学习运动速度,框架提出了一种基于光流的运动幅度控制方法。通过计算光流的平均幅度并将其投影到位置嵌入中,可以在所有帧中一致地应用运动强度。视频生成:在推理阶段,用户点击的位置和简短的动作提示被用来生成动画视频。模型结合了用户指定的区域掩码和动作提示,生成了一系列连贯的动画帧,同时保持了输入图像的其余部分静止。 相关推荐