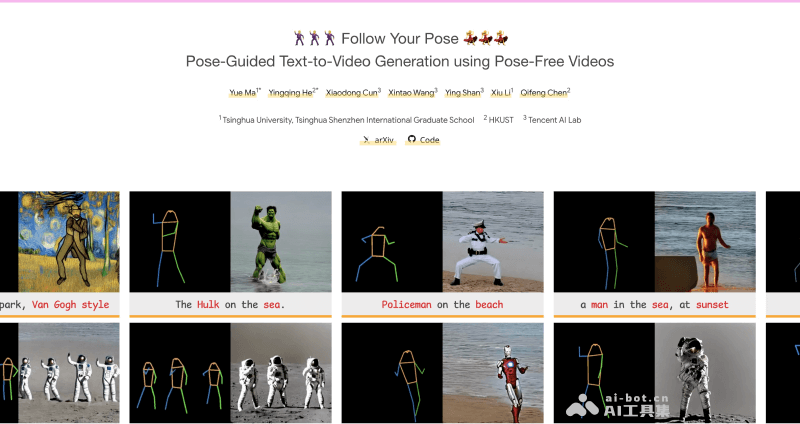
Follow Your Pose-开源的姿态全可控视频生成框架
文章来源:智汇AI 发布时间:2025-08-07
Follow Your Pose是由清华大学、香港科技大学、腾讯AI Lab以及中科院的研究人员开源的一个基于文本到视频生成的框架,允许用户通过文本描述和指定的
暂无访问Follow Your Pose是什么
Follow Your Pose是由清华大学、香港科技大学、腾讯AI Lab以及中科院的研究人员开源的一个基于文本到视频生成的框架,允许用户通过文本描述和指定的人物姿态来生成视频。该框架采用了两阶段的训练策略,能够生成与文本描述和姿态序列高度一致的视频,同时保持视频中人物动作的真实性和连贯性。
Follow Your Pose的官网入口
官方项目主页:https://follow-your-pose.github.io/GitHub代码库:https://github.com/mayuelala/FollowYourPoseArxiv研究论文:https://arxiv.org/abs/2304.01186Hugging Face运行地址:https://huggingface.co/spaces/YueMafighting/FollowYourPoseOpenXLab运行地址:https://openxlab.org.cn/apps/detail/houshaowei/FollowYourPoseGoogle Colab运行地址:https://colab.research.google.com/github/mayuelala/FollowYourPose/blob/main/quick_demo.ipynbFollow Your Pose的功能特色
文本到视频生成:用户可以输入文本描述,框架会根据这些描述生成相应的视频内容,如角色的动作、场景背景以及整体的视觉风格。姿态控制:用户可以通过指定人物的姿态序列来控制视频中角色的动作,以精确地控制角色在视频中的每一个动作细节。时间连贯性:框架能够生成时间上连贯的视频,确保视频中的动作和场景变化自然流畅,没有突兀的跳跃或闪烁。多样化角色和背景生成:框架能够生成具有不同外观、风格和背景的视频,包括但不限于现实风格、卡通风格、赛博朋克风格等。多角色视频生成:框架支持多角色视频的生成,可以在同一个视频中展示多个角色,并且能够根据文本描述指定每个角色的身份和动作。风格化视频生成:用户可以通过添加风格描述(如“卡通风格”、“赛博朋克风格”等)来生成具有特定艺术风格的视频。Follow Your Pose的工作原理
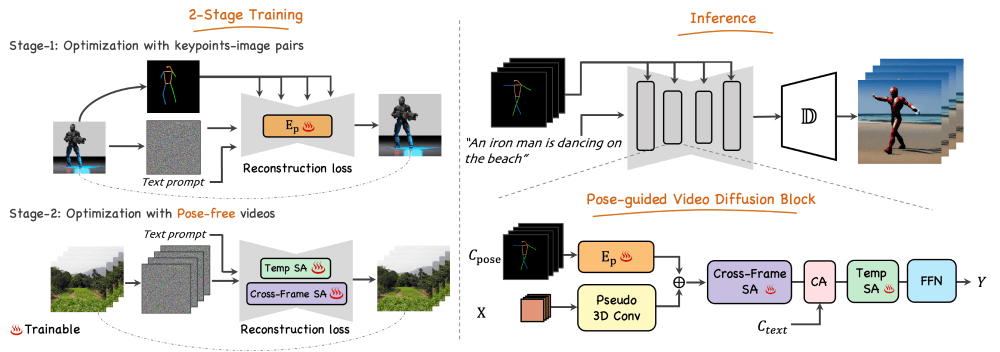
Follow Your Pose的工作原理主要基于一个两阶段的训练过程,旨在结合文本描述和姿态信息来生成视频。以下是其工作原理的详细步骤:
第一阶段:姿态控制的文本到图像生成姿态编码器:首先,框架使用一个零初始化的卷积编码器来学习姿态信息。这个编码器从输入的姿态序列中提取关键点特征。特征注入:提取的姿态特征被下采样到不同的分辨率,并以残差连接的方式注入到预训练的文本到图像(T2I)模型的U-Net结构中。这样做可以在保持原有模型的图像生成能力的同时,引入姿态控制。训练:在这个阶段,模型仅使用姿态图像对进行训练,目的是学习如何根据文本描述和姿态信息生成图像。第二阶段:视频生成视频数据集:为了学习时间上的连贯性,框架在第二阶段使用了一个没有姿态标注的视频数据集(如HDVLIA)进行训练。3D网络结构:将预训练的U-Net模型扩展为3D网络,以便处理视频输入。这涉及到将第一层卷积扩展为伪3D卷积,并添加时间自注意力模块来模拟时间序列。跨帧自注意力:为了进一步提高视频的连贯性,框架引入了跨帧自注意力(cross-frame self-attention)模块,这有助于在视频帧之间保持内容的一致性。微调:在这个阶段,只有与时间连贯性相关的参数(如时间自注意力和跨帧自注意力)会被更新,而其他参数(如伪3D卷积层和前馈网络FFN)保持不变。生成过程文本和姿态输入:在推理阶段,用户输入描述目标角色外观和动作的文本,以及一个表示动作序列的姿态序列。视频生成:模型根据这些输入生成视频。在生成过程中,大多数预训练的稳定扩散模型参数被冻结,只有与时间连贯性相关的模块参与计算。通过这种两阶段的训练策略,Follow Your Pose能够有效地从易于获取的数据集中学习,生成具有高度控制性和时间连贯性的视频。
相关推荐