Self Forcing-Adobe联合德克萨斯大学推出的视频生成模型
文章来源:智汇AI 发布时间:2025-08-11
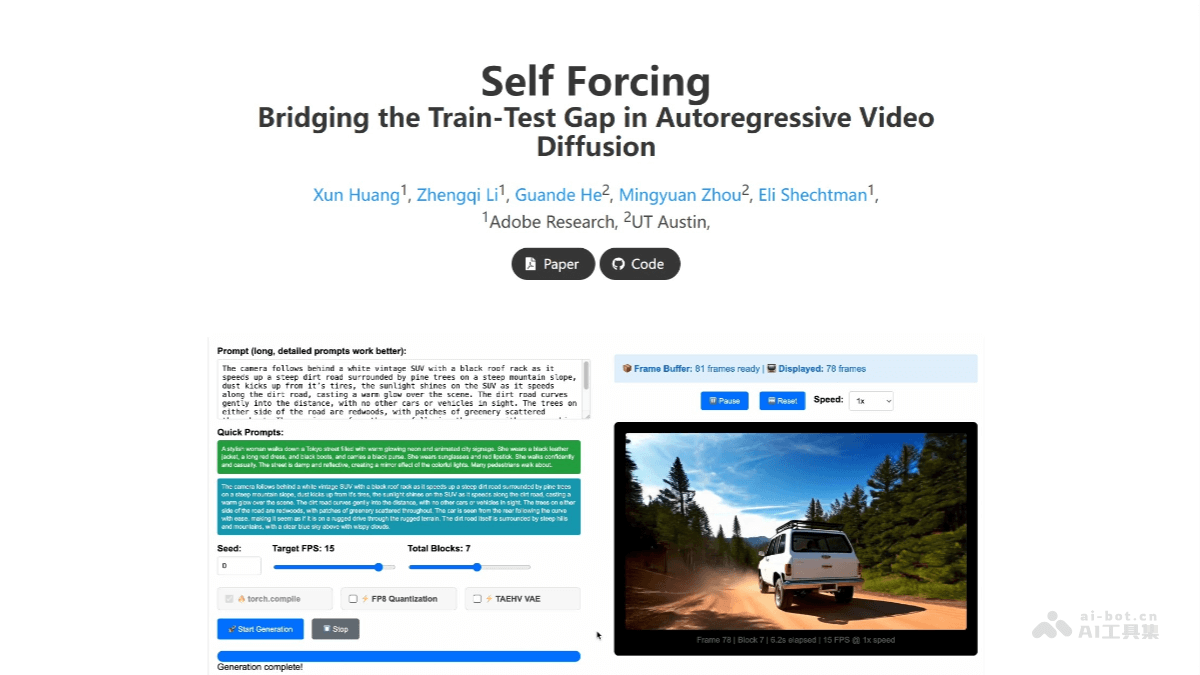
Self Forcing 是 Adobe Research 与德克萨斯大学奥斯汀分校联合推出的新型自回归视频生成算法,解决传统生成模型在训练与测试时的暴露偏差问
暂无访问Self Forcing是什么
Self Forcing 是 Adobe Research 与德克萨斯大学奥斯汀分校联合推出的新型自回归视频生成算法,解决传统生成模型在训练与测试时的暴露偏差问题。通过在训练阶段模拟自生成过程,以先前生成的帧为条件生成后续帧,而非依赖真实帧,弥合训练与测试分布的差异。Self Forcing 引入滚动 KV 缓存机制,支持理论上无限长的视频生成,在单个 H100 GPU 上实现 17 FPS 的实时生成能力,延迟低于一秒。突破为直播、游戏和实时交互应用提供了新的可能性,例如实时生成虚拟背景或特效。Self Forcing 的高效性和低延迟成为未来多模态内容创作的重要工具。
Self Forcing的主要功能
高效实时视频生成:Self Forcing 能在单个 GPU 上实现高效的实时视频生成,帧率达到 17 FPS,延迟低于一秒。无限长视频生成:通过滚动 KV 缓存机制,Self Forcing 支持理论上无限长的视频生成。可以持续生成视频内容,不会因长度限制而中断,为动态视频创作提供了强大的支持。弥合训练与测试差距:Self Forcing 在训练阶段模拟自生成过程,以生成的帧为条件生成后续帧,而非依赖真实帧。有效解决了自回归生成中的暴露偏差问题,弥合了训练与测试阶段的分布差异,提高了生成视频的质量和稳定性。低资源需求:Self Forcing 优化了计算资源的使用,能在单张 RTX 4090 显卡上实现流式视频生成,降低了对硬件资源的依赖,更易于在普通设备上部署和使用。支持多模态内容创作:Self Forcing 的高效性和实时性使其能够为多模态内容创作提供支持,例如在游戏直播中实时生成背景或特效,或者在虚拟现实体验中动态生成视觉内容,为创作者提供了更广阔的应用空间。Self Forcing的技术原理
自回归展开与整体损失监督:Self Forcing 在训练阶段模拟了推理时的自回归生成过程,即每一帧的生成都基于模型自身之前生成的帧,而非真实帧。通过视频级别的整体分布匹配损失函数对整个生成序列进行监督,不仅是逐帧评估。模型能直接从自身预测的错误中学习,有效减轻暴露偏差。相关推荐