GLM-4.1V-Thinking-智谱AI开源的视觉语言模型系列
文章来源:智汇AI 发布时间:2025-08-12
GLM-4.1V-Thinking是智谱AI推出的开源视觉语言模型,专为复杂认知任务设计,支持图像、视频、文档等多模态输入。模型在GLM-4V架构基础上引入思维
暂无访问GLM-4.1V-Thinking是什么
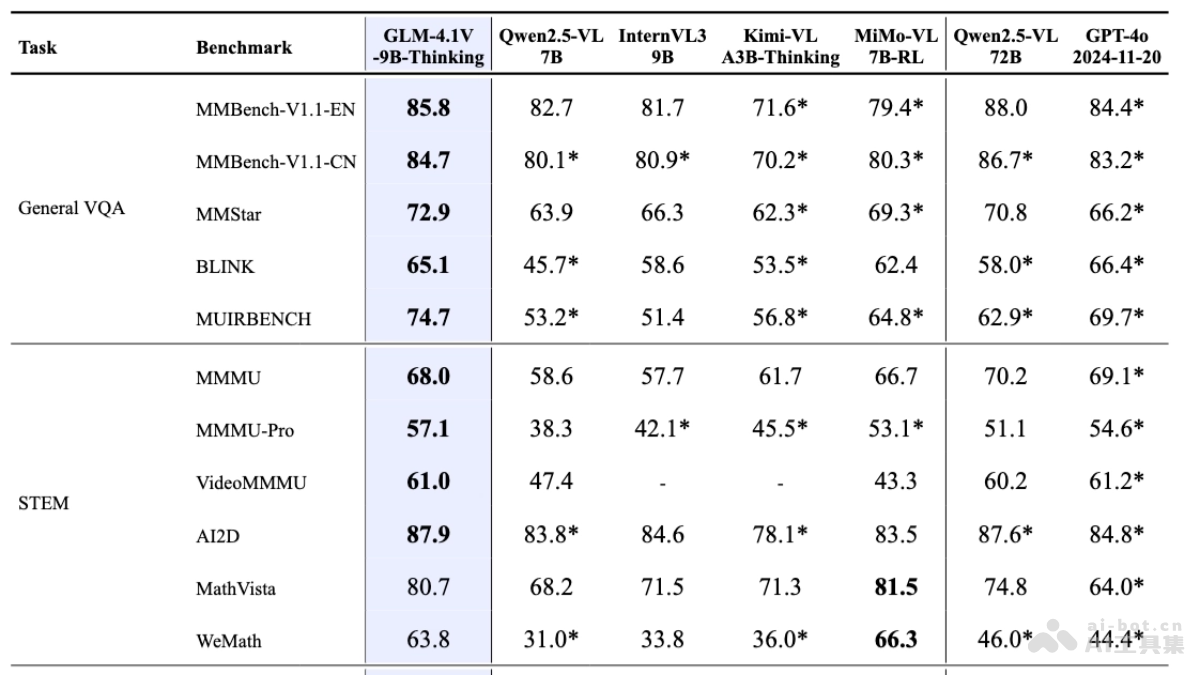
GLM-4.1V-Thinking是智谱AI推出的开源视觉语言模型,专为复杂认知任务设计,支持图像、视频、文档等多模态输入。模型在GLM-4V架构基础上引入思维链推理机制,基于课程采样强化学习策略,系统性提升跨模态因果推理能力与稳定性。模型轻量版GLM-4.1V-9B-Thinking(GLM-4.1V-9B-Base基座模型和GLM-4.1V-9B-Thinking具备深度思考和推理能力)参数量控制在10B级别,在28项权威评测中,有23项达成10B级模型最佳成绩,其中18项持平或超越参数量高达72B的Qwen-2.5-VL,展现出小体积模型的极限性能潜力。
GLM-4.1V-Thinking的主要功能
图像理解:精准识别和分析图像内容,支持复杂的视觉任务,如目标检测、图像分类和视觉问答。视频处理:具备时序分析和事件逻辑建模能力,支持处理视频输入,进行视频理解、视频描述和视频问答。文档解析:支持处理文档中的图像和文本内容,支持长文档理解、图表理解和文档问答。数学与科学推理:支持复杂的数学题解、多步演绎和公式理解,能处理STEM领域的推理任务。逻辑推理:支持进行逻辑推理和因果分析,支持复杂的推理任务,如多步推理和逻辑判断。跨模态推理:合视觉和语言信息进行推理,支持图文理解、视觉问答和视觉锚定等任务。GLM-4.1V-Thinking的技术原理
架构设计:基于AIMv2Huge作为视觉编码器,处理和编码图像和视频输入。MLP适配器将视觉特征对齐到语言模型的token空间。语言解码器用GLM作为语言模型,处理多模态token并生成输出。训练方法:基于大规模的图像-文本对、学术文献和知识密集型数据进行预训练,构建强大的视觉语言基础模型。用长链推理(CoT)数据进行监督微调,提升模型的推理能力和人类对齐。基于课程采样强化学习(RLCS),动态选择最具信息量的样本进行训练,提升模型在多种任务上的性能。技术创新:引入思维链推理机制,让模型逐步思考生成详细的推理过程。基于课程采样策略,动态调整训练样本的难度,确保模型在不同阶段都能获得最有效的训练。基于2D-RoPE和3D-RoPE技术,支持任意分辨率和宽高比的图像输入,增强模型的时空理解能力。GLM-4.1V-Thinking的性能表现
模型在MMStar、MMMU-Pro、ChartQAPro、OSWorld等28项权威评测中,有23项达成10B级模型的最佳成绩,其中18项持平或超越参数量高达72B的Qwen-2.5-VL。
GLM-4.1V-Thinking的项目地址
GitHub仓库:https://github.com/THUDM/GLM-4.1V-ThinkingHuggingFace模型库:https://huggingface.co/collections/THUDM/glm-41v-thinking-6862bbfc44593a8601c2578darXiv技术论文:https://arxiv.org/pdf/2507.01006v1在线体验Demo:https://huggingface.co/spaces/THUDM/GLM-4.1V-9B-Thinking-Demo如何使用GLM-4.1V-Thinking
API接口:注册账号:访问智谱AI开放平台,注册账号并登录。相关推荐