Qwen-Image-阿里通义千问开源的文生图模型
文章来源:智汇AI 发布时间:2025-08-14
Qwen-Image 是阿里通义千问团队开源的 20B 参数MMDiT模型,是通义千问系列中首个图像生成基础模型,模型在复杂文本渲染和精确图像编辑方面表现出色,
暂无访问Qwen-Image是什么
Qwen-Image 是阿里通义千问团队开源的 20B 参数MMDiT模型,是通义千问系列中首个图像生成基础模型,模型在复杂文本渲染和精确图像编辑方面表现出色,支持多行布局、段落级文本生成及细粒度细节呈现,中英文都能实现高保真输出。Qwen-Image 在通用图像生成和编辑任务中展现出强大的能力,支持多种艺术风格和高级编辑操作。目前用户可通过Qwen Chat,图像生成功能体验模型性能。
Qwen-Image的主要功能
复杂文本渲染:支持多行和段落文本生成,能清晰呈现细小文字,擅长中文和英文渲染。精确图像编辑:支持风格迁移、对象增删改、细节增强、文字编辑和人物姿态调整,并保持图像自然和真实感。通用图像生成:支持多种艺术风格,能根据用户描述生成创意图像。Qwen-Image的技术原理
模型架构:基于先进的多模态大语言模型(MLLM)作为文本特征提取模块,能精准理解文本语义并转化为图像生成所需的特征。变分自编码器(VAE)负责将输入图像编码为紧凑的潜在表示,在推理阶段进行解码,实现图像的高效处理和生成。模型核心部分是多模态扩散变换器(MMDiT),基于逐步去除噪声生成图像,结合文本特征进行引导,确保生成的图像与文本描述高度一致。数据处理:通过大规模的数据收集和标注,构建涵盖自然、设计、人物和合成数据的丰富数据集。基于多阶段的数据过滤流程,逐步去除低质量或不符合要求的数据,确保数据的高质量和多样性。训练策略:在训练过程中,用流匹配(Flow Matching)作为预训练目标,用普通微分方程(ODE)实现稳定的训练动态,同时保持与最大似然目标的等价性。模型结合文本到图像(T2I)、图像到图像(I2I)和文本图像到图像(TI2I)的多任务训练范式,基于共享潜在空间实现多任务学习。Qwen-Image的性能表现
总体性能表现:多基准测试领先:Qwen-Image在多个公开基准测试中获得了12项最佳表现(SOTA),在图像生成和编辑领域具有很强的竞争力。超越头部模型:在通用图像生成测试(如GenEval、DPG和OneIG-Bench)和图像编辑测试(如GEdit、ImgEdit和GSO)中,Qwen-Image超过Flux.1、BAGEL等开源模型,且超过字节跳动的SeedDream 3.0和OpenAI的GPT Image 1(High)等闭源模型。Qwen-Image在生成质量和编辑能力上都达到较高的水平。文本渲染能力表现:文本渲染基准测试:在LongText-Bench、ChineseWord和TextCraft等基准测试中,Qwen-Image表现尤为出色,特别是在中文文本渲染方面,大幅领先现有的最先进模型,如SeedDream 3.0和GPT Image 1(High)。中文文本渲染优势:Qwen-Image在处理中文文本渲染时具有独特的优势,在语言理解、字体生成、排版等方面有更优化的技术,能更好地适应中文的复杂性和多样性。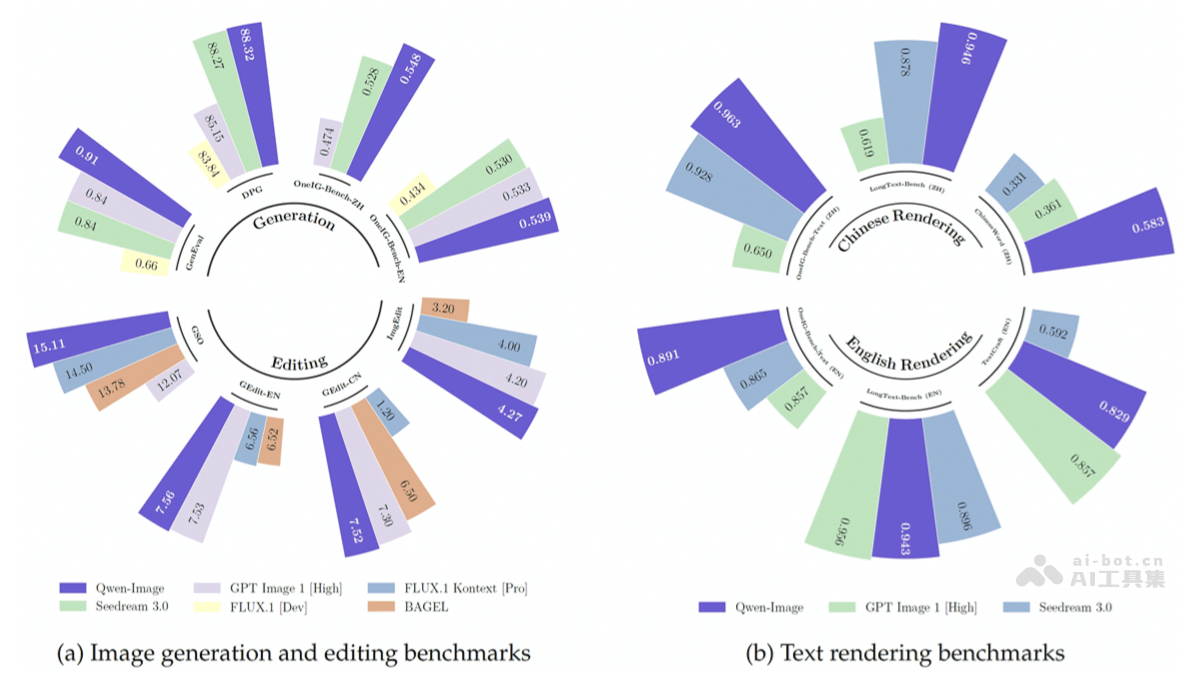
如何使用Qwen-Image
访问 QwenChat:访问 Qwen Chat 官方网站。选择图像生成功能:在 QwenChat 的界面中,找到并选择“图像生成”功能。输入文本提示:在文本输入框中输入想要生成图像的描述。生成图像:点击“生成”按钮,Qwen-Image 根据文本提示生成图像。查看和下载生成的图像:生成的图像显示在界面上,用户能查看生成的效果,选择下载保存到本地。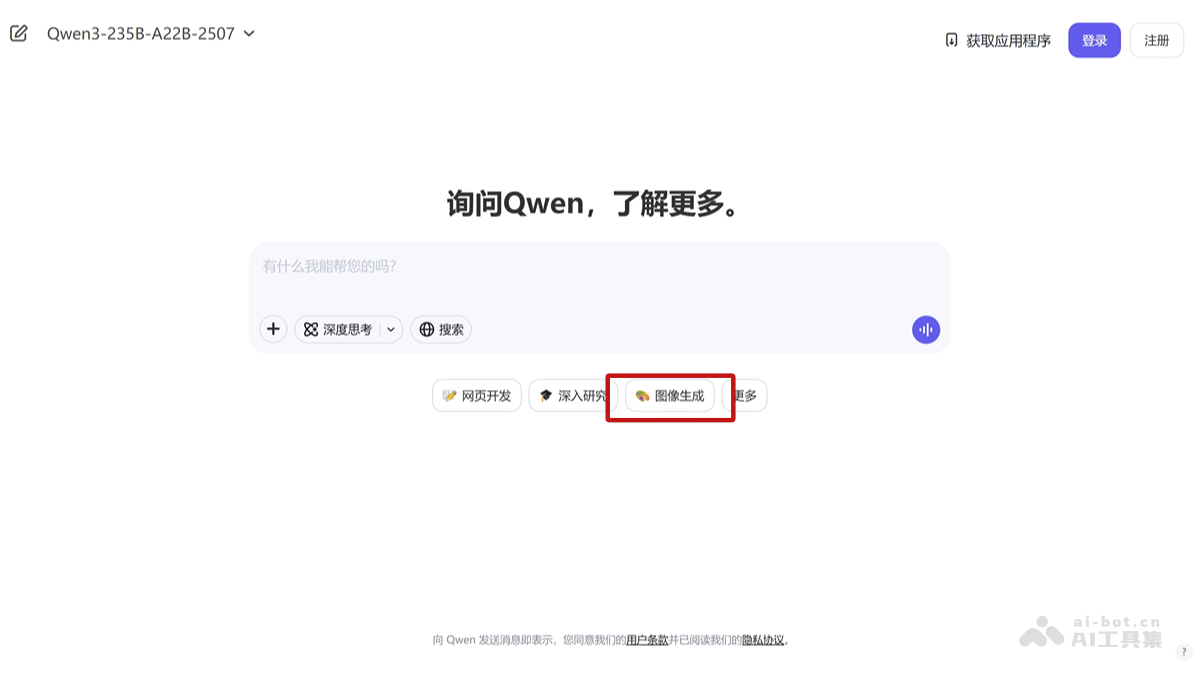
Qwen-Image的项目地址
GitHub仓库:https://github.com/QwenLM/Qwen-ImageHuggingFace模型库:https://huggingface.co/Qwen/Qwen-Image技术论文:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-Image/Qwen_Image.pdf在线体验Demo:https://huggingface.co/spaces/Qwen/Qwen-ImageQwen-Image的应用场景
内容创作:根据文本描述快速生成高质量的图像、海报和PPT页面,极大地提升创意设计和演示文稿的制作效率与视觉效果。艺术与设计:模型能轻松实现风格迁移和创意绘画,为艺术家和设计师提供丰富的灵感来源,加速艺术作品的创作过程。教育与学习:通过生成教学材料和语言学习相关的图像,帮助教师更生动地传授知识,辅助学习者更好地理解和记忆。商业与营销:在商业领域快速生成吸引人的广告图像和品牌推广素材,有效提升广告的吸引力和品牌的市场影响力。娱乐与游戏:用在生成游戏中的角色、场景和道具图像,及影视制作中的特效和概念图,加速娱乐内容的创作周期。相关推荐