EchoMimicV3-蚂蚁集团推出的多模态数字人视频生成框架
文章来源:智汇AI 发布时间:2025-08-26
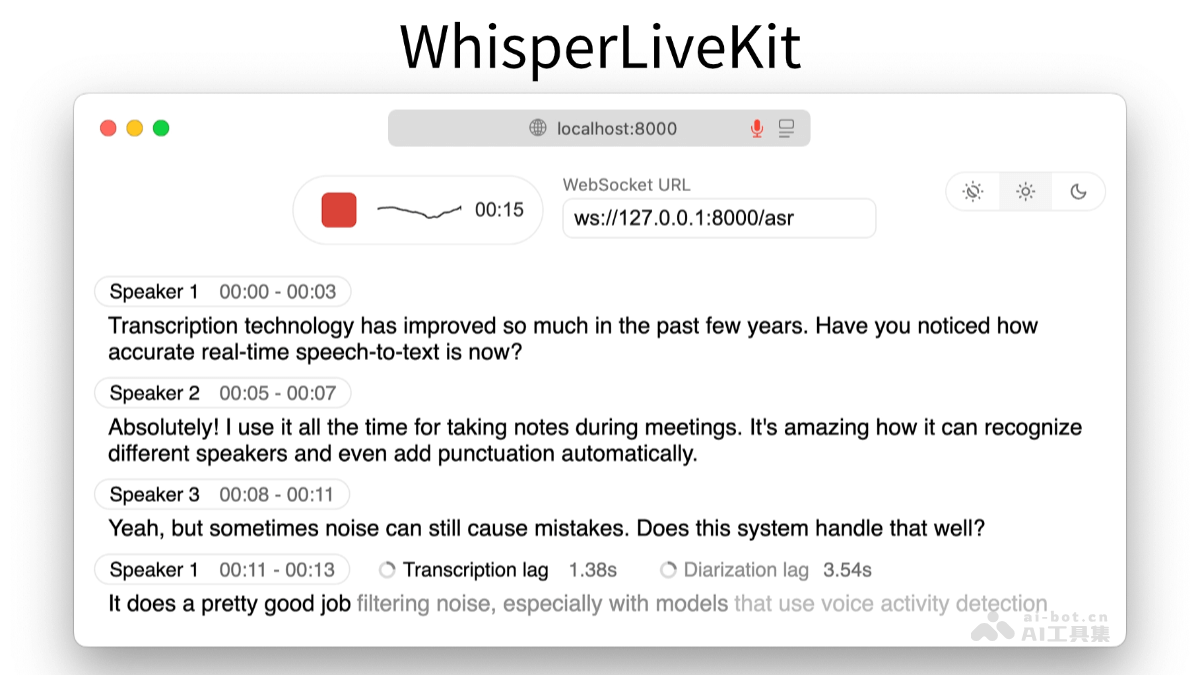
EchoMimicV3是蚂蚁集团推出的高效多模态、多任务数字人视频生成框架。框架拥有13亿参数,基于任务混合和模态混合范式,结合新颖的训练与推理策略,实现快速、
暂无访问EchoMimicV3是什么
EchoMimicV3是蚂蚁集团推出的高效多模态、多任务数字人视频生成框架。框架拥有13亿参数,基于任务混合和模态混合范式,结合新颖的训练与推理策略,实现快速、高质量、强泛化的数字人视频生成。EchoMimicV3基于多任务掩码输入和反直觉任务分配策略,及耦合-解耦多模态交叉注意力模块和时间步相位感知多模态分配机制,让模型在仅13亿参数下,能在多种任务和模态下表现出色,为数字人动画领域带来重大突破。
EchoMimicV3的主要功能
多模态输入支持:模型能处理多种模态的输入,包括音频、文本、图像等,实现更丰富和自然的人类动画生成。多任务统一框架:将多种任务整合到一个模型中,如音频驱动的面部动画、文本到动作生成、图像驱动的姿态预测等。高效推理与训练:在保持高性能的同时,基于优化的训练策略和推理机制,实现高效的模型训练和快速的动画生成。高质量动画生成:支持生成高质量、自然流畅的数字人动画。框架生成的动画在细节和连贯性上表现出色,能满足各种应用场景的需求。强泛化能力:模型具有良好的泛化能力,能适应不同的输入条件和任务需求。EchoMimicV3的技术原理
任务混合范式(Soup-of-Tasks):EchoMimicV3用多任务掩码输入和反直觉的任务分配策略。模型能在训练过程中同时学习多个任务,实现多任务的增益无需多模型的痛苦。模态混合范式(Soup-of-Modals):引入耦合-解耦多模态交叉注意力模块,用在注入多模态条件。结合时间步相位感知多模态分配机制,动态调整多模态混合。负直接偏好优化(Negative Direct Preference Optimization)和相位感知负分类器自由引导(Phase-aware Negative Classifier-Free Guidance):两种技术确保模型在训练和推理过程中的稳定性。基于优化训练过程中的偏好学习和引导机制,模型能更好地处理复杂的输入和任务需求,避免训练过程中的不稳定性和生成结果的退化。Transformer架构:EchoMimicV3基于Transformer架构构建,用强大的序列建模能力处理时间序列数据。Transformer架构的自注意力机制使模型能有效地捕捉输入数据中的长距离依赖关系,生成更加自然和连贯的动画。大规模预训练与微调:模型通过在大规模数据集上进行预训练,学习通用的特征表示和知识。在特定任务上进行微调,适应具体的动画生成需求。预训练加微调的策略使模型能充分利用大量的无监督数据,提高模型的泛化能力和性能。EchoMimicV3的项目地址
项目官网:https://antgroup.github.io/ai/echomimic_v3/GitHub仓库:https://github.com/antgroup/echomimic_v3HuggingFace模型库:https://huggingface.co/BadToBest/EchoMimicV3arXiv技术论文:https://arxiv.org/pdf/2507.03905EchoMimicV3的应用场景
虚拟角色动画:在游戏、动画电影和虚拟现实(VR)中,根据音频、文本或图像生成虚拟角色的面部表情和身体动作,让角色更加生动逼真,提升沉浸感。特效制作:在影视特效中,快速生成高质量的人物动态表情和肢体动作,减少人工建模和动画制作的时间与成本,提高制作效率。虚拟代言人:在广告和营销领域,创建虚拟代言人,根据品牌需求生成符合品牌形象的动画内容,用在广告宣传和社交媒体推广,增强品牌影响力。虚拟教师:在在线教育平台生成虚拟教师的动画,根据教学内容和语音讲解呈现相应表情和动作,让教学过程更生动有趣,提升学生学习兴趣。虚拟社交:在社交平台,用户生成自己的虚拟形象,根据语音或文字输入实时生成表情和动作,增强社交互动性和趣味性。相关推荐