StepAudio R1-阶跃星辰开源的原生音频推理模型
文章来源:智汇AI 发布时间:2025-11-29
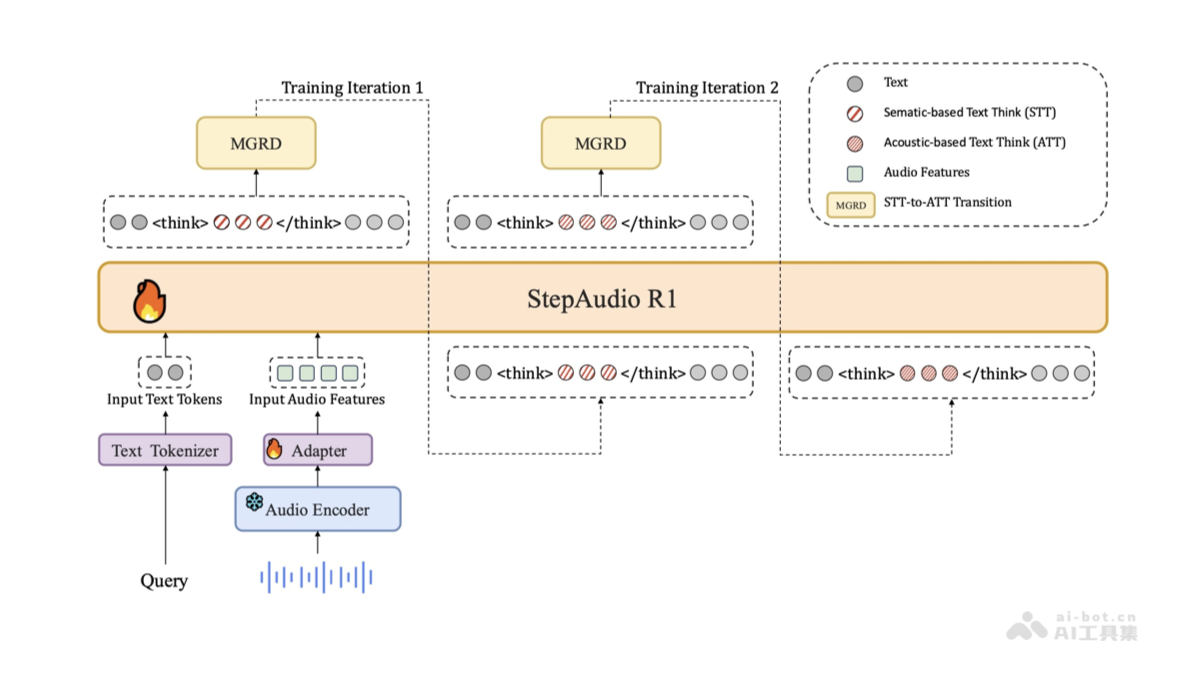
StepAudio R1 是阶跃星辰团队推出的全球首个开源原生音频推理模型。模型通过创新的模态锚定推理蒸馏(MGRD)框架,解决了传统音频模型在复杂推理中性能下
暂无访问StepAudio R1是什么
StepAudio R1 是阶跃星辰团队推出的全球首个开源原生音频推理模型。模型通过创新的模态锚定推理蒸馏(MGRD)框架,解决了传统音频模型在复杂推理中性能下降的问题,真正实现基于声学特征的深度推理。在多项基准测试中,StepAudio R1 超越 Gemini 2.5 Pro,与 Gemini 3 相当。模型具备极高的实时推理能力,评分达 96%,首包延迟仅 0.92 秒。模型为音频领域的多模态推理开辟了新路径,广泛应用在歌曲赏析、影视分析、访谈分析等场景,为音频智能处理带来革命性突破。
StepAudio R1的主要功能
复杂音频推理:StepAudio R1 能处理复杂的音频推理任务,例如理解对话中的隐含意义、分析情感、推断人物特征等。实时音频推理:模型具备强大的实时推理能力,能在极低延迟(如 0.92 秒的首包延迟)下进行推理,适合实时对话和交互场景。多模态推理能力:StepAudio R1 专注音频,能结合文本推理能力,成为多模态任务中的通用解决方案。情感与社会智能推理:模型能分析音频中的情感、人物特质、社会关系等,例如通过对话推断人物的心理状态、性格特征或社会身份。StepAudio R1的技术原理
模态锚定推理蒸馏(MGRD):StepAudio R1 的核心技术是模态锚定推理蒸馏(Modality-Grounded Reasoning Distillation)。框架通过迭代的自蒸馏训练,将推理能力从文本抽象转移到声学属性上。解决传统音频模型中推理链与音频模态对齐不足的问题,使模型能生成真正基于声学特征的推理链。音频特征提取与对齐:模型首先提取音频的关键特征(如语调、节奏、情感等),通过 MGRD 框架将特征与推理任务对齐,确保推理过程始终基于音频本身的特性,不依赖文本转录或其他模态的替代。多模态融合:StepAudio R1 保留了文本推理能力,使其能处理多模态任务。融合能力使其在处理复杂的多模态场景时更具优势,例如结合音频和文本进行情感分析或内容理解。StepAudio R1的项目地址
项目官网:https://stepaudiollm.github.io/step-audio-r1/GitHub仓库:https://github.com/stepfun-ai/Step-Audio-R1HuggingFace模型库:https://huggingface.co/stepfun-ai/Step-Audio-R1arXiv技术论文:https://arxiv.org/pdf/2511.15848StepAudio R1的应用场景
音乐赏析:分析歌曲的旋律、歌词情感、风格特点等,帮助用户更好地理解音乐作品的内涵。相关推荐


















