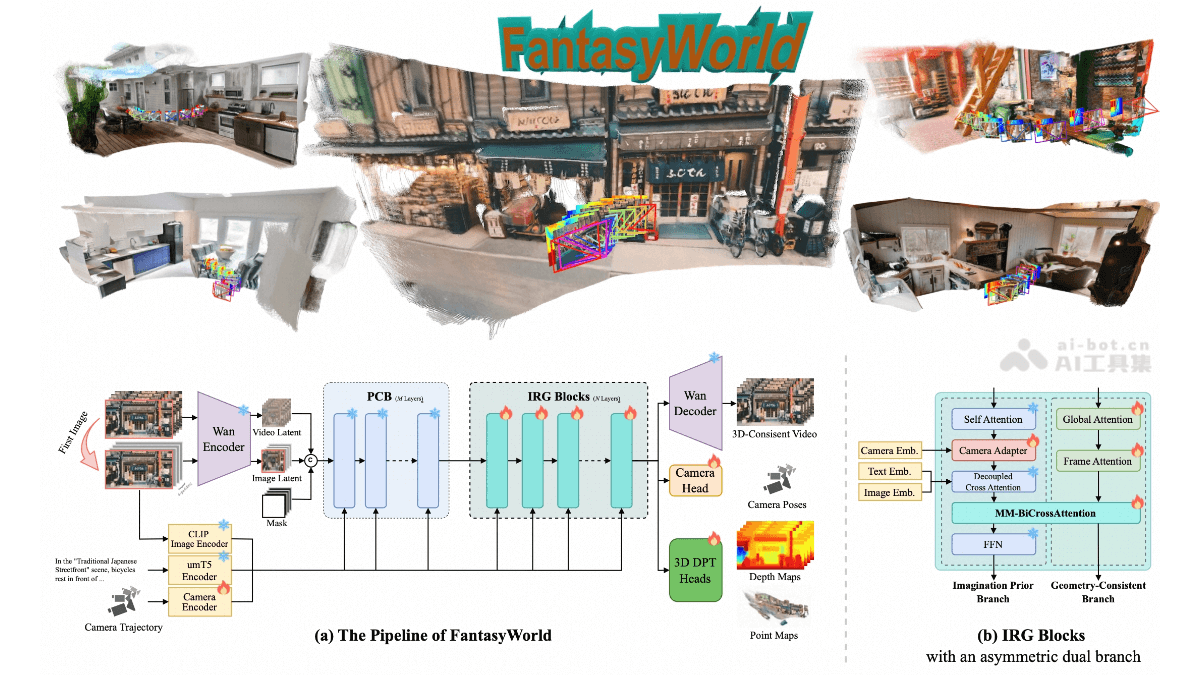
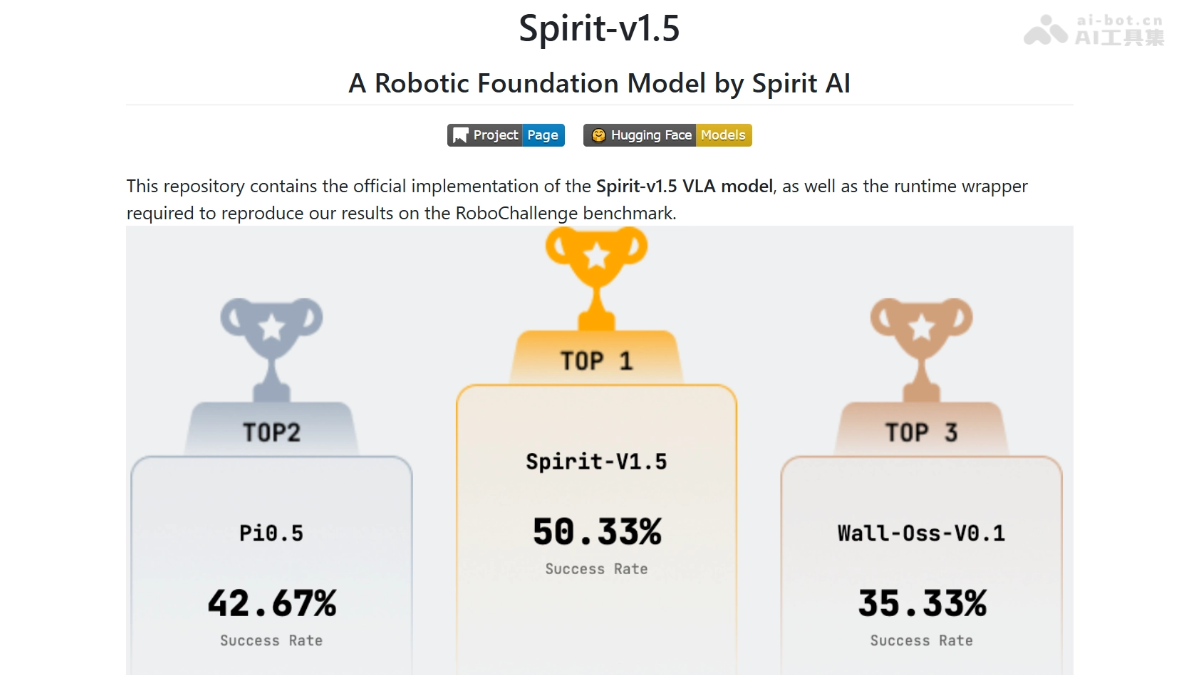
Nemotron Speech ASR-英伟达开源的语音识别模型
文章来源:智汇AI 发布时间:2026-01-14
Nemotron Speech ASR 是英伟达开源的专注于低延迟、实时流式语音识别的模型。通过缓存感知架构,将已处理的语音特征缓存,仅对新音频帧进行计算,实现
暂无访问Nemotron Speech ASR是什么
Nemotron Speech ASR 是英伟达开源的专注于低延迟、实时流式语音识别的模型。通过缓存感知架构,将已处理的语音特征缓存,仅对新音频帧进行计算,实现单句转录锁定仅需24毫秒,有效解决了传统流式模型在长语音识别中的累积延迟问题。模型支持多档延迟模式(80ms、160ms、560ms、1.12s),可根据应用场景灵活调整,无需重新训练,适用于游戏语音、实时翻译、会议记录等多种场景。具备更高的吞吐量和更低的运行成本,端到端延迟控制在500毫秒以内,并原生支持标点符号和大小写。
Nemotron Speech ASR的主要功能
低延迟实时识别:专为低延迟、实时流式场景设计,单句转录锁定仅需24毫秒,几乎与人类神经反应速度相当,适用于对实时性要求极高的语音交互场景。相关推荐