本地部署AI必看教程:(二)本地AI大语言模型部署+数据库
文章来源:智汇AI 发布时间:8780-06-09
本文导航:本地部署AI必看教程:(一)拯救C盘计划本地部署AI必看教程:(二)拯救C盘计划第二部分、打造支持本地RAG的AI大语言模型这次,我们以新出的Llama3.18b举例,首先,
暂无访问本文导航。
,我在此就不多做赘述了。
我们在装好ollama后,打命令行窗口,使用下面命令下载Llama 3.1 8b。
ollama run llama3.1:8b
下载完成后,使用下面的代码来安装 Open WebUI,根据你的情况选择 GPU/CPU/服务器的版本。
1、安装支持 NVIDIA GPU 的 Open WebUI(推荐)。
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
2、仅CPU。
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
3、如果Ollama在服务器上。
#将代码中的 [OLLAMA_BASE_URL] 更改为你服务器的URL
docker run -d -p 3000:8080 -e OLLAMA_BASE_URL=https://example.com -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
4、仅用于 OpenAI API 的 Open WebUI。
#将代码中的 [your_secret_key] 换成你的Key
docker run -d -p 3000:8080 -e OPENAI_API_KEY=your_secret_key -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
5、Ollama捆绑+GPU 的 Open WebUI。
docker run -d -p 3000:8080 --gpus=all -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
6、Ollama捆绑+仅CPU 的 Open WebUI。
docker run -d -p 3000:8080 -v ollama:/root/.ollama -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:ollama
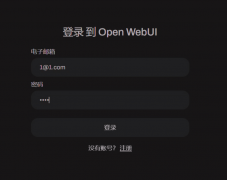
安装搞定后,在docker界面点击3000端口,即可打开Open WebUI
选择工作空间→选择文档tab,+号上传你的文档,别忘了给你的文档命名和打上标签。
接着,我们回到对话界面,用#号选择所有文档,大家可以看看喂文档前后的答案,应对我们日常生活中的大多数问题,绰绰有余了。
至于更进阶的如何搭建自己的RAG向量数据库,怎么利用AI来快捷编写方便AI认识的的RAG 也就是JSON和XML文件来训练AI,我们下期教程再说!
OK,教程到此结束,关注智汇AI网站,每天更新一点精品AI教程内容。
相关推荐