Pix2Gif-微软推出的静态图像转动态GIF的扩散模型
文章来源:智汇AI 发布时间:2025-08-06
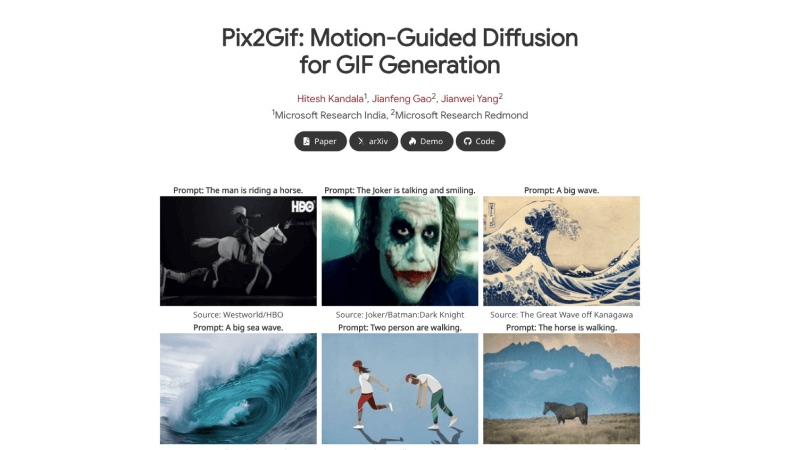
Pix2Gif是由微软研究院的研究人员提出的一个基于运动引导的扩散模型,专门用于将静态图像转换成动态的GIF动画 视频。该模型通过运动引导的扩散过程来实现图像到
暂无访问Pix2Gif是什么
Pix2Gif是由微软研究院的研究人员提出的一个基于运动引导的扩散模型,专门用于将静态图像转换成动态的GIF动画/视频。该模型通过运动引导的扩散过程来实现单张图像到GIF的生成,利用文本描述和运动幅度提示作为输入,来引导图像内容的动态变化。此外,Pix2Gif还引入了感知损失,以保持生成的GIF帧与目标图像在视觉上的一致性和连贯性。
Pix2Gif的官网入口
官方项目主页:https://hiteshk03.github.io/Pix2Gif/arXiv研究论文:https://arxiv.org/abs/2403.04634GitHub代码库:https://github.com/hiteshK03/Pix2Gif在线Demo体验:https://520a83a7524ec7d864.gradio.live/Pix2Gif的功能特性
文本引导的动画生成:用户可以通过输入文本描述来指导模型生成符合特定主题或动作的GIF动画,模型会根据文本内容理解并创造出相应的动态视觉效果。运动幅度控制:Pix2Gif允许用户指定运动幅度,从而控制GIF中动作的强度和速度。这为用户提供了精细的运动控制能力,可创造出从缓慢微妙到快速剧烈的不同动态效果。运动引导的图像变换:模型使用运动引导变形模块来根据文本提示和运动幅度在空间上变换源图像的特征,创造出连贯的动态帧。感知损失优化:为了确保生成的GIF在视觉上与源图像保持一致,Pix2Gif采用了感知损失函数,以保持高级视觉特征的一致性,如颜色、纹理和形状等。Pix2Gif的工作原理
Pix2Gif的工作原理基于扩散模型的原理,结合了文本引导和运动幅度控制来生成动态GIF动画。以下是Pix2Gif工作原理的详细步骤:
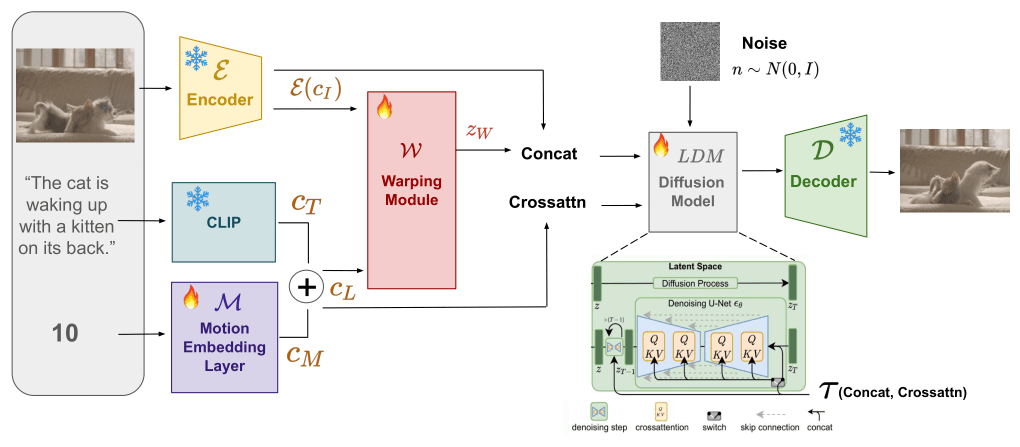 输入处理:文本提示:用户提供一个描述所需动画内容的文本提示。运动幅度:用户还可以指定一个运动幅度值,该值量化了期望在GIF中表现的运动强度。特征提取与编码:源图像编码:源图像通过一个编码器(例如VQ-VAE)转换成潜在空间中的向量表示。文本嵌入:文本提示通过预训练的语言模型(如CLIP)处理,得到文本的嵌入表示。运动嵌入:运动幅度值也被嵌入为一个向量,以便与文本嵌入一起作为模型的条件输入。运动引导变形:FlowNet (FNet):一个子网络,根据文本和运动嵌入生成一个光流特征图,该图表示图像中的运动方向和幅度。WarpNet (WNet):另一个子网络,它使用光流特征图和源图像的潜在表示来生成一个变形后的潜在表示。潜在扩散过程:逆扩散:Pix2Gif模型在潜在空间中执行逆扩散过程,这是一个逐步去除噪声以生成清晰图像的过程。条件生成:在逆扩散过程中,模型使用文本嵌入和运动嵌入作为条件,引导生成过程以符合用户的输入提示。感知损失:高级特征一致性:为了确保生成的图像在视觉上与源图像保持一致,模型使用感知损失函数,这通常涉及到比较预训练深度网络(如VGG网络)中的特征图。输出生成:图像解码:最终,模型输出的潜在表示被解码成像素空间中的图像帧,形成动态的GIF动画。端到端训练:优化:整个模型通过端到端的方式进行训练,最小化由真实图像、文本提示和运动幅度定义的损失函数。
输入处理:文本提示:用户提供一个描述所需动画内容的文本提示。运动幅度:用户还可以指定一个运动幅度值,该值量化了期望在GIF中表现的运动强度。特征提取与编码:源图像编码:源图像通过一个编码器(例如VQ-VAE)转换成潜在空间中的向量表示。文本嵌入:文本提示通过预训练的语言模型(如CLIP)处理,得到文本的嵌入表示。运动嵌入:运动幅度值也被嵌入为一个向量,以便与文本嵌入一起作为模型的条件输入。运动引导变形:FlowNet (FNet):一个子网络,根据文本和运动嵌入生成一个光流特征图,该图表示图像中的运动方向和幅度。WarpNet (WNet):另一个子网络,它使用光流特征图和源图像的潜在表示来生成一个变形后的潜在表示。潜在扩散过程:逆扩散:Pix2Gif模型在潜在空间中执行逆扩散过程,这是一个逐步去除噪声以生成清晰图像的过程。条件生成:在逆扩散过程中,模型使用文本嵌入和运动嵌入作为条件,引导生成过程以符合用户的输入提示。感知损失:高级特征一致性:为了确保生成的图像在视觉上与源图像保持一致,模型使用感知损失函数,这通常涉及到比较预训练深度网络(如VGG网络)中的特征图。输出生成:图像解码:最终,模型输出的潜在表示被解码成像素空间中的图像帧,形成动态的GIF动画。端到端训练:优化:整个模型通过端到端的方式进行训练,最小化由真实图像、文本提示和运动幅度定义的损失函数。 相关推荐