Vary-toy:开源的小型视觉多模态模型
文章来源:智汇AI 发布时间:2025-08-07
Vary-toy是一个小型的视觉语言模型(LVLM),由来自旷视、国科大、华中大的研究人员共同提出,旨在解决大型视觉语言模型(LVLMs)在训练和部署上的挑战。
暂无访问Vary-toy是什么
Vary-toy是一个小型的视觉语言模型(LVLM),由来自旷视、国科大、华中大的研究人员共同提出,旨在解决大型视觉语言模型(LVLMs)在训练和部署上的挑战。对于资源有限的研究者来说,大型模型通常拥有数十亿参数,难以在消费级GPU上(如GTX 1080Ti)进行训练和部署。Vary-toy的核心目标便是让研究人员能够在有限的硬件资源下,体验到当前LVLMs的所有功能(文档OCR、视觉定位、图像描述、视觉文答等)。

Vary-toy的主要功能
文档级光学字符识别(OCR):Vary-toy能够识别和理解文档图像中的文字,这在处理扫描文档、PDF文件等场景中非常有用。图像描述:模型能够生成图像的描述性文本,这对于图像内容的理解和生成图像描述任务(如VQA)至关重要。视觉问答(VQA):Vary-toy能够回答关于图像内容的问题,这涉及到理解图像的视觉信息以及与之相关的文本信息。对象检测:通过强化的视觉词汇,Vary-toy具备了自然对象感知(定位)的能力,能够在图像中识别和定位物体。图像到文本的转换:Vary-toy可以将图像内容转换为结构化的文本格式,例如将PDF图像转换为Markdown格式。多模态对话:Vary-toy模型支持多模态对话,能够理解和生成与图像内容相关的对话。Vary-toy的官方入口
官方项目主页:https://varytoy.github.io/Arxiv研究论文:https://arxiv.org/abs/2401.12503Demo运行地址:https://vary.xiaomy.net/GitHub代码库:https://github.com/Ucas-HaoranWei/Vary-toyVary-toy的技术原理
Vary-toy的工作原理基于几个关键的技术和设计决策,这些决策共同作用于提高模型在视觉语言任务上的性能,同时保持模型的小型化。以下是Vary-toy工作原理的主要组成部分:
视觉词汇生成:Vary-toy利用一个小型的自回归模型(OPT-125M)来生成新的视觉词汇网络。这个网络通过处理PDF图像文本对和自然图像中的对象检测数据来学习如何有效地编码视觉信息。与传统的Vary模型相比,Vary-toy在生成视觉词汇时,不再将自然图像作为负样本,而是将其视为正样本,从而更充分地利用网络的容量。视觉词汇与CLIP的融合:在生成新的视觉词汇后,Vary-toy将其与原始的CLIP(Contrastive Language-Image Pre-training)模型相结合。CLIP是一个强大的视觉-语言模型,能够将图像和文本映射到共享的嵌入空间。通过这种方式,Vary-toy能够利用CLIP的图像理解能力,同时通过新的视觉词汇网络增强对文本信息的处理。多任务预训练:Vary-toy在预训练阶段采用了多任务学习策略,这意味着模型在训练过程中同时处理多种类型的数据,如图像描述、PDF OCR、对象检测、纯文本对话和视觉问答(VQA)。这种多任务训练有助于模型学习更丰富的视觉和语言表示,提高其在各种下游任务上的泛化能力。模型结构:Vary-toy遵循Vary的管道设计,但在结构上有所调整。当输入图像时,新的视觉词汇分支会将图像调整到1024×1024的分辨率,而CLIP分支则通过中心裁剪获取224×224的图像。两个分支输出的图像特征被合并,作为输入到1.8B参数的Qwen-1.8B语言模型中。数据输入格式:为了适应不同的任务,Vary-toy需要处理多种输入格式。例如,对于PDF图像-文本对,模型使用了一个特定的提示(如“Provide the OCR results of this image.”)来指导输出正确的结果。对于对象检测任务,模型使用不同的提示模板来处理图像中的多个对象。微调(SFT):在预训练之后,Vary-toy通过指令调优(SFT)阶段进一步优化模型。这个阶段使用LLaVA-80K数据集,这是一个包含详细描述和提示的图像数据集,由GPT4生成。这有助于模型更好地理解和生成与图像内容相关的文本。通过这些工作机制,Vary-toy能够在保持模型小型化的同时,实现对复杂视觉语言任务的有效处理。这种设计使得Vary-toy成为一个在资源受限环境中进行视觉语言研究的有力工具。
如何使用Vary-toy
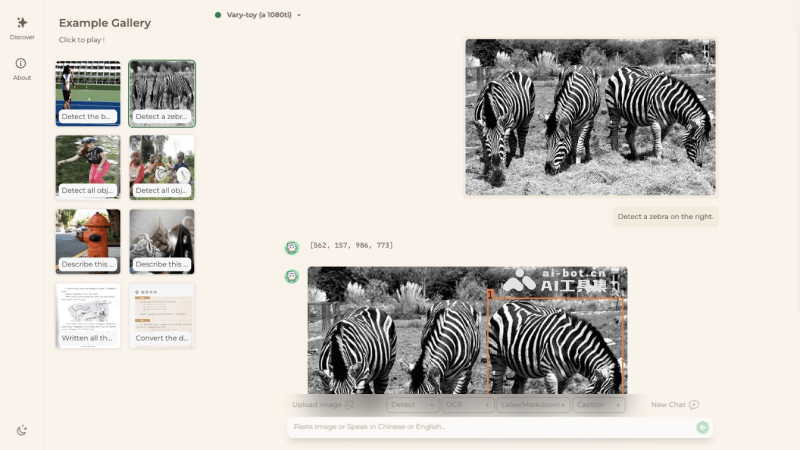
访问Vary-toy的官方demo体验地址(vary.xiaomy.net)点击上传一张图片或者在左侧选择示例图片输入提示指令如描述图像内容、检测图像中的物体等等待模型生成结果即可相关推荐