VibeVoice-微软推出的开源文本转语音模型
文章来源:智汇AI 发布时间:2025-08-27
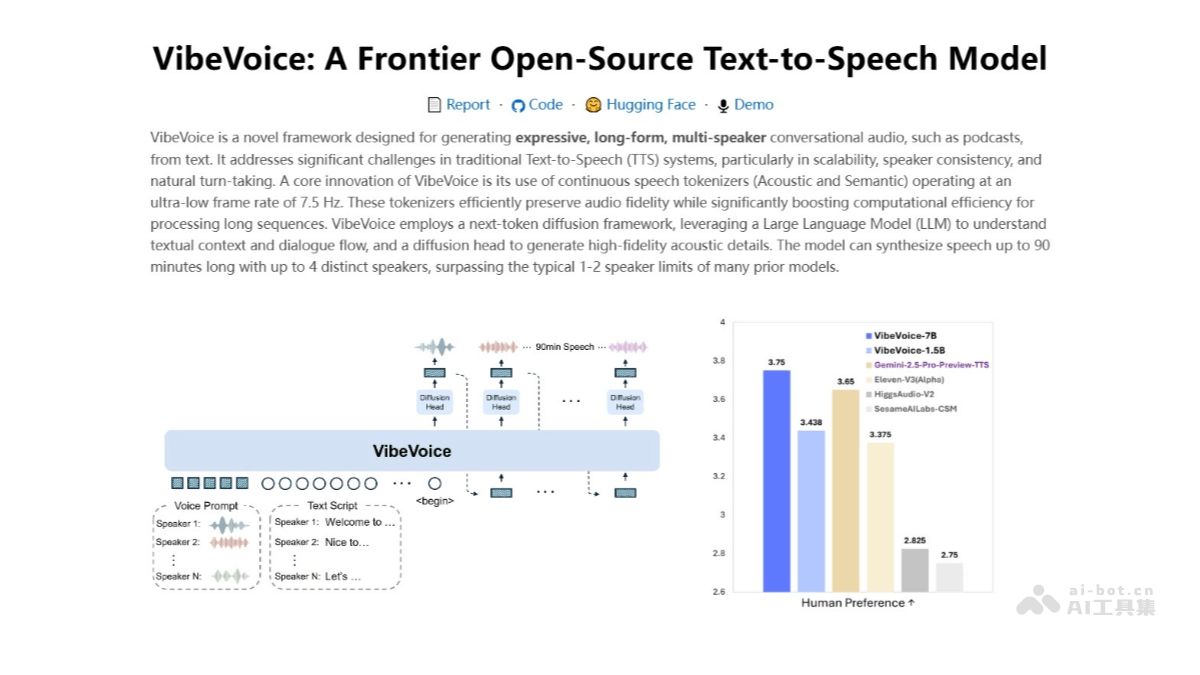
VibeVoice 是微软推出的新型文本到语音(TTS)模型,能生成富有表现力、长篇幅、多说话者的对话式音频,如播客。
暂无访问VibeVoice是什么
VibeVoice 是微软推出的新型文本到语音(TTS)模型,能生成富有表现力、长篇幅、多说话者的对话式音频,如播客。模型通过创新的连续语音标记化技术和下一代标记扩散框架,结合大型语言模型(LLM),实现高效处理长序列音频的能力,同时保持高保真度。VibeVoice 能合成长达90分钟的语音,支持多达4位不同说话者,突破传统TTS系统的限制,为自然对话和情感表达提供新的可能。
VibeVoice的主要功能
多说话者支持:能生成多达4位不同说话者的对话式音频,适用播客、有声读物等场景。长篇幅对话:支持生成长达90分钟的连续语音,突破传统TTS系统在长度上的限制。富有表现力的语音:根据文本内容生成带有情感和语调的语音,让对话更加自然和生动。跨语言支持:支持多种语言的语音合成,能处理跨语言的对话场景。高保真音频:生成的语音质量高,接近人类的自然语音,提供更好的用户体验。实时交互:能实时生成语音,支持动态对话和交互式应用。VibeVoice的技术原理
连续语音标记化:用连续的语音标记化技术,将音频信号分解为语义和声学标记。标记用极低的帧率(如7.5 Hz)运行,提高计算效率,同时保留音频的高保真度。语义标记器(Semantic Tokenizer)负责处理文本内容,提取语义信息;声学标记器(Acoustic Tokenizer)负责生成具体的音频细节。下一代标记扩散框架:基于扩散模型的生成框架,结合大型语言模型(LLM)理解文本上下文和对话流程。扩散模型通过逐步细化生成的音频标记,最终生成高质量的语音信号。多说话者一致性:通过特定的说话者嵌入(Speaker Embeddings)技术,确保不同说话者的声音特征在长篇幅对话中保持一致。模型支持多说话者的语音合成,能自然地处理说话者之间的切换和对话流程。高保真音频生成:用先进的声码器(Vocoder)技术,将生成的标记转换为高质量的音频信号。通过优化声码器的参数,确保生成的语音在音质上接近人类的自然语音。VibeVoice的项目地址
项目官网:https://microsoft.github.io/VibeVoice/GitHub仓库:https://github.com/microsoft/VibeVoiceHuggingFace模型库:https://huggingface.co/collections/microsoft/vibevoice-68a2ef24a875c44be47b034f技术论文:https://github.com/microsoft/VibeVoice/blob/main/report/TechnicalReport.pdfVibeVoice的应用场景
播客制作:支持生成多达4位不同说话者的对话式音频,支持长达90分钟的连续语音,非常适合制作多主持人播客节目,让播客内容更加丰富多样。有声读物:生成富有情感和语调的语音,让有声读物更加生动有趣,提升听众的阅读体验。虚拟助手:生成的语音自然流畅,适合用于虚拟助手的语音交互,为用户提供更加人性化的服务,增强用户体验。教育和培训:适合模拟课堂讨论等教学场景,情感表达功能让互动式教学材料更加生动,提高学习效果。娱乐和游戏:为虚拟角色生成富有表现力的语音,增强游戏和互动娱乐应用的沉浸感,让玩家有更真实的体验。相关推荐