ParseStudio:简化PDF解析的Python库
文章来源:智汇AI 发布时间:2025-06-07
ParseStudio是一个强大的 Python 库,专门用于从PDF文档中提取和解析内容。它提供了直观的接口,可以处理多种任务,如提取文本、表格和图
暂无访问ParseStudio是什么?
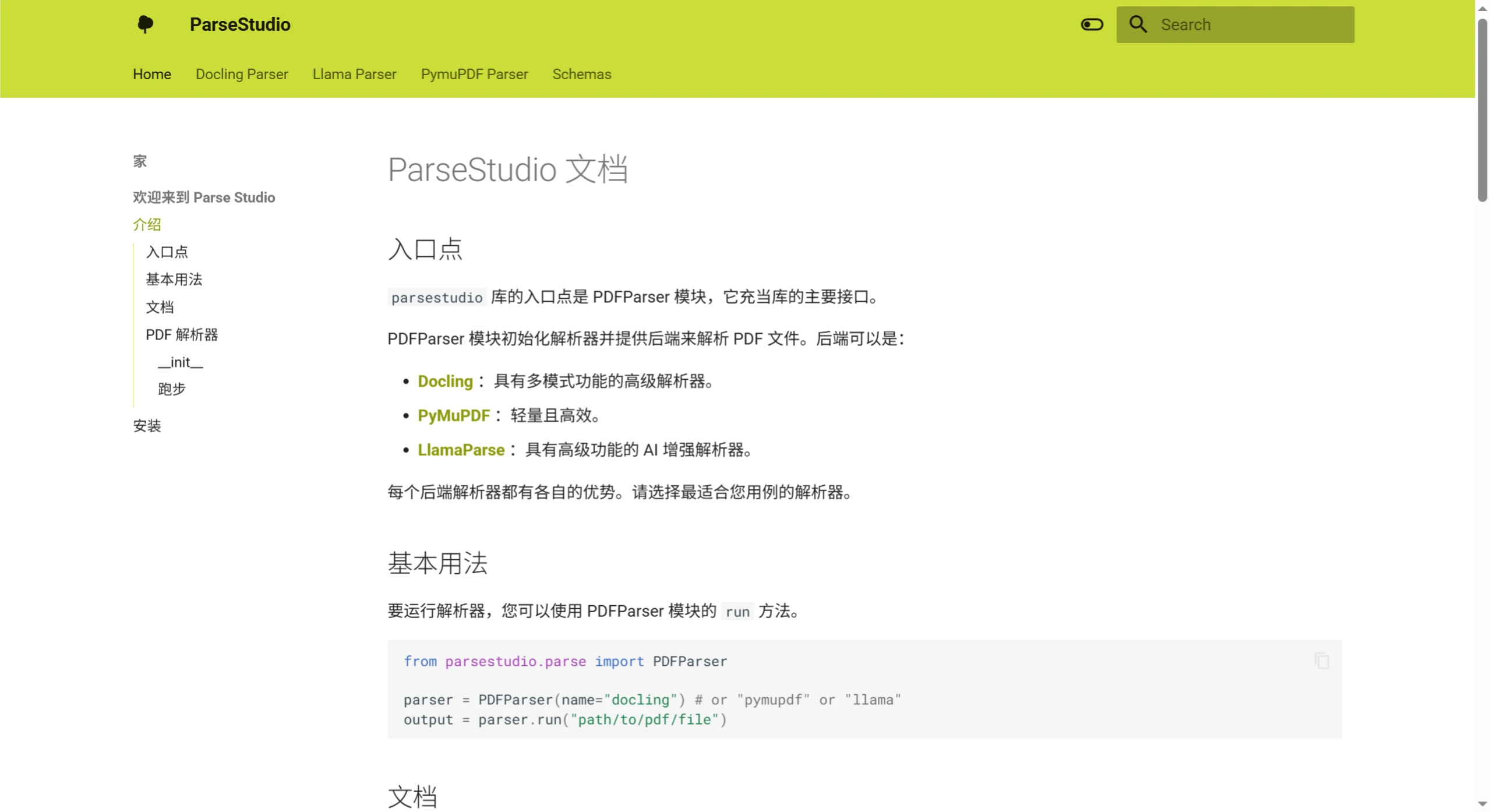
处理PDF文档时,提取文本、表格和图片常常很麻烦,而且不同库的用法各不相同,这使得代码变得重复且难以管理。ParseStudio这个Python库提供了一种简化的方法,它将多个解析器整合到一个统一的接口中,用户仅需几行代码就能完成PDF文档的解析工作。该库整合了Docling、PyMuPDF和Llama Parse这三种引擎,能够灵活地处理文本、表格和图片的提取任务。ParseStudio的主要特点有:模块化的设计、能够同时提取多种类型的内容、简洁的API设计、可以将表格自动转换为Markdown格式、提取图片时会包含元数据,以及支持批量处理多个PDF文件。对于有一定Python基础的开发者来说,ParseStudio是一个实用的工具。
ParseStudio主要特点
模块化设计:可以选择多种解析后端,如 Docling、PyMuPDF 和 Llama Parse,以满足不同需求。
多模态解析:能够无缝提取文本、表格和图像。
统一语法:通过提供统一的接口,简化了与不同后端的交互。
可扩展性:可以通过额外的参数轻松调整解析行为。
用户友好:抽象了后端特定的复杂性,使用户可以专注于提取内容。
ParseStudio安装方法
使用 pip 安装:
pipinstallparsestudio从源代码安装:
gitclonehttps://github.com/chatclimate-ai/ParseStudio.gitcdParseStudiopipinstall.ParseStudio快速入门
导入并初始化解析器:
fromparsestudio.parseimportPDFParser#使用所需的解析器后端初始化parser=PDFParser(parser="docling")#选项:"docling"、"pymupdf"、"llama"解析 PDF 文件:
outputs=parser.run(["path/to/file.pdf"],modalities=["text","tables","images"])#访问文本内容print(outputs[0].text)#访问表格fortableinoutputs[0].tables:print(table.markdown)#访问图像forimageinoutputs[0].images:image.image.show()metadata=image.metadataprint(metadata)支持的解析器
Docling:适合复杂文档的详细布局分析,支持 OCR 和精确的表格提取。
PyMuPDF:轻量级且高效,适合快速处理。
LlamaParse:基于云和 AI 增强的提取,适合需要高级功能的场景。
Github:https://github.com/chatclimate-ai/ParseStudio
相关推荐