




让记账像点外卖一样简单
直击痛点,3秒完成极速记账

沁言学术AI的产品功能
超级智能体
沁言AI如何处理以及有
找文献、读文献、管文献、写论

OpenWork-开源
OpenWork 是开源的桌

Prompt Mana
Prompt Manager

FrogBoss-微软
FrogBoss 是微软研究

NovaSR-开源音频
NovaSR 是开源的音频超

Playwriter-
Playwriter 是开源

VerseCrafte
VerseCrafter 是

PersonaPlex
NVIDIA Persona

GLM-4.7-Fla
GLM-4.7-Flash

COTA-超参数科技推
COTA是超参数科技推出的新

x-Algorithm
x-Algorithm是马斯

Step3-VL-10
Step3-VL-10B 是

EmbodiChain
EmbodiChain 是跨

json-render
json-render是 V

Model1-Deep
Model1 是 DeepS

Chroma 1.0-
Chroma 1.0 是Fl

AgentCPM-Re
AgentCPM-Repor

VibeVoice-A
VibeVoice-ASR

Being-H0.5-
Being-H0.5 是卢宗

LightOnOCR-
LightOnOCR-2-1

TranslateGe
TranslateGemma

FLUX.2 [kle
FLUX.2 [klein]

AgentCPM-Ex
AgentCPM-Explo

ArenaRL-通义与
ArenaRL 是通义 De

Step-Audio-
Step-Audio-R1.

GLM-Image-智
GLM-Image 是智谱联
VidBee-开源音视
VidBee 是开源的视频下
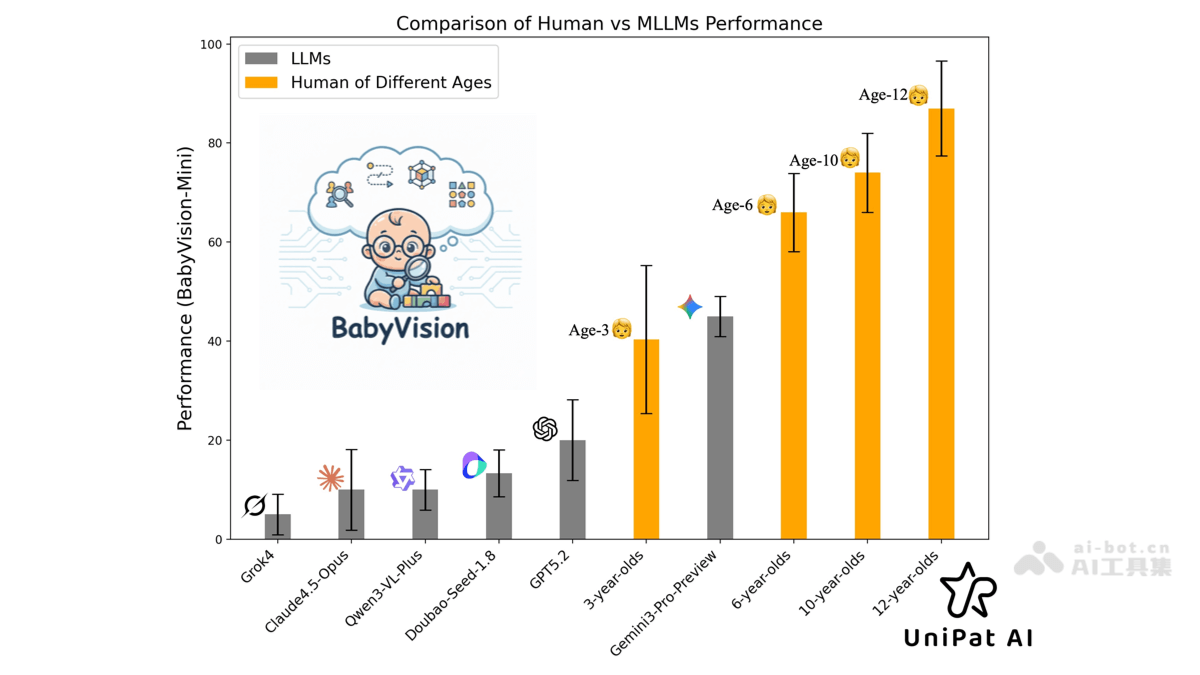
BabyVision-
BabyVision是 Un

PixVerse R1
PixVerse R1 是爱

司农-南京农业大学开源
司农(司农大语言模型)是南京

OctoCodingB
OctoCodingBenc

MedGemma 1.
MedGemma 1.5 是
DeepTutor-香
DeepTutor 是香港大

Nemotron Sp
Nemotron Speec