



Obsidian-sk
Obsidian-skill
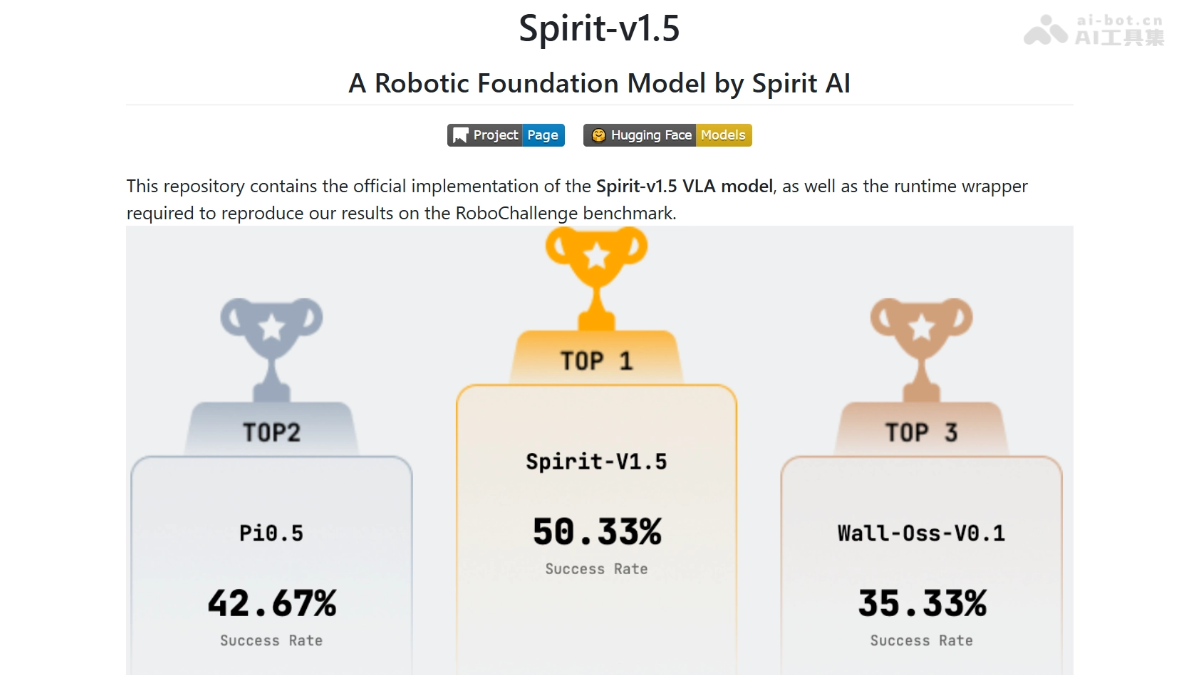
Spirit-v1.5
Spirit-v1.5 是千
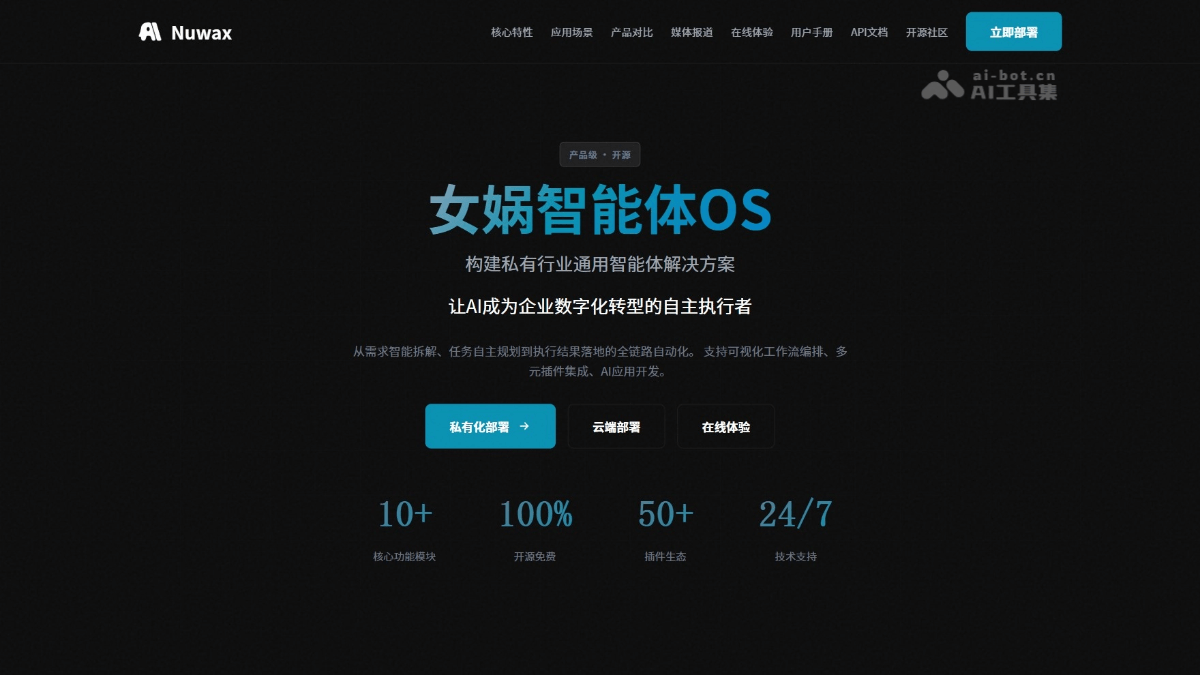
女娲智能体OS-首个产
女娲智能体OS(Nuwax

Oh My OpenC
Oh My OpenCode

Engram-Deep
Engram 是DeepSe

Baichuan-M3
Baichuan-M3是百川
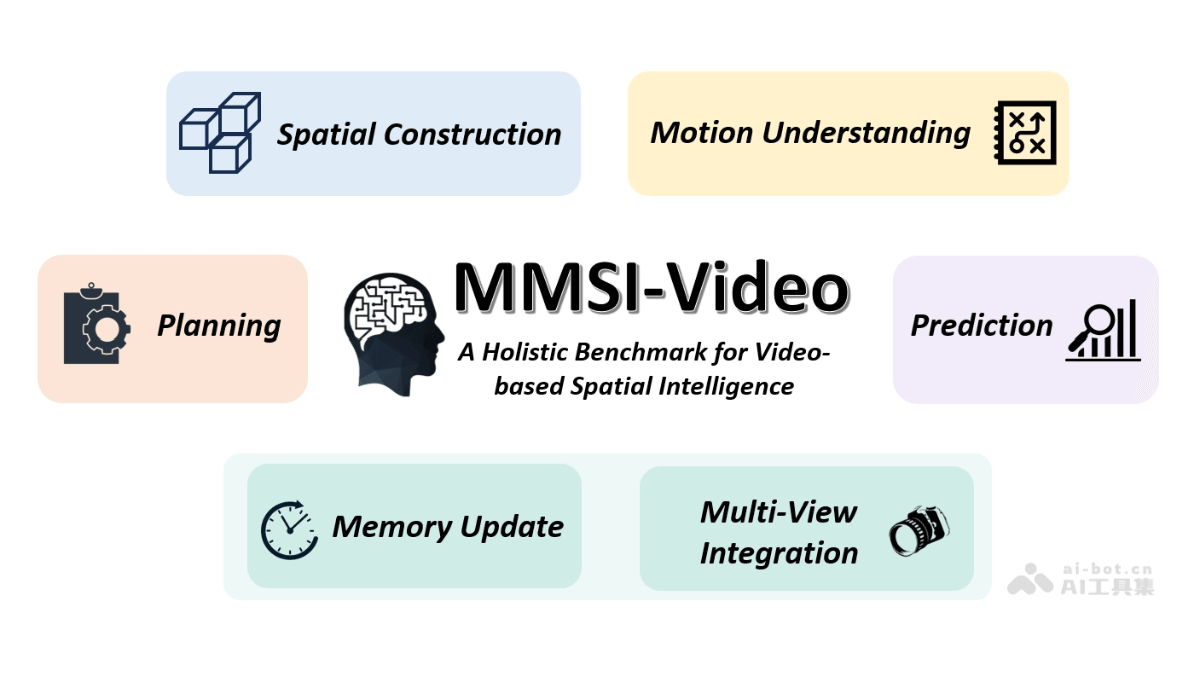
MMSI-Video-
MMSI-Video-Ben
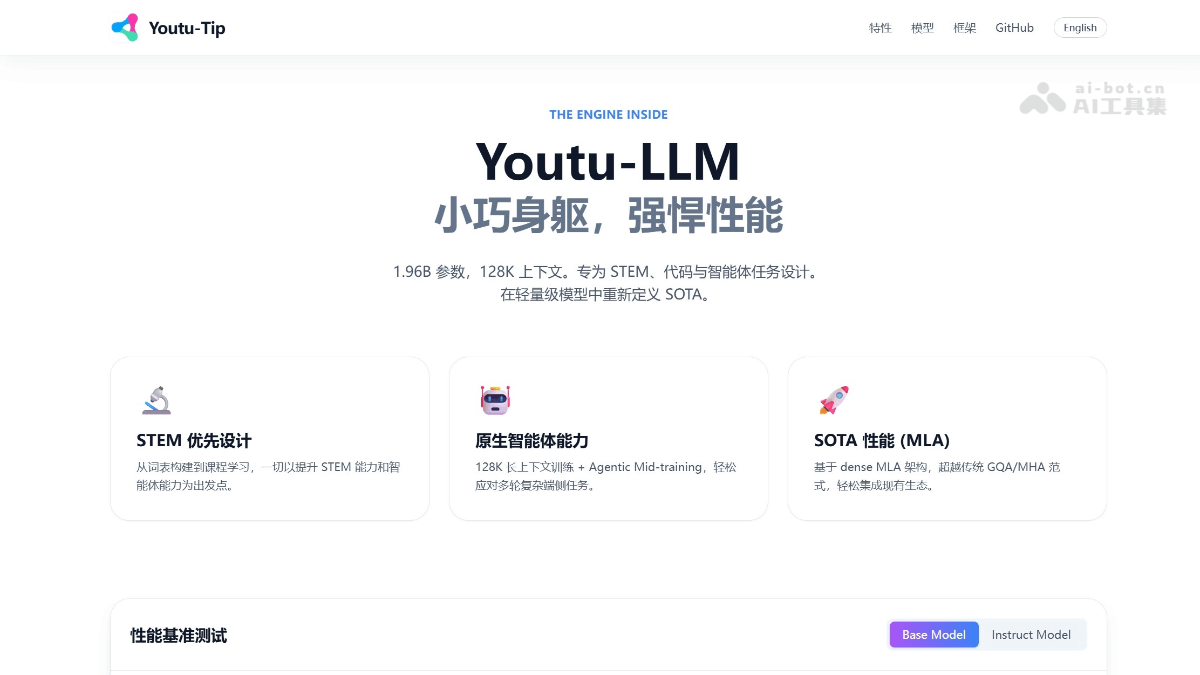
Youtu-LLM-腾
Youtu-LLM 是腾讯
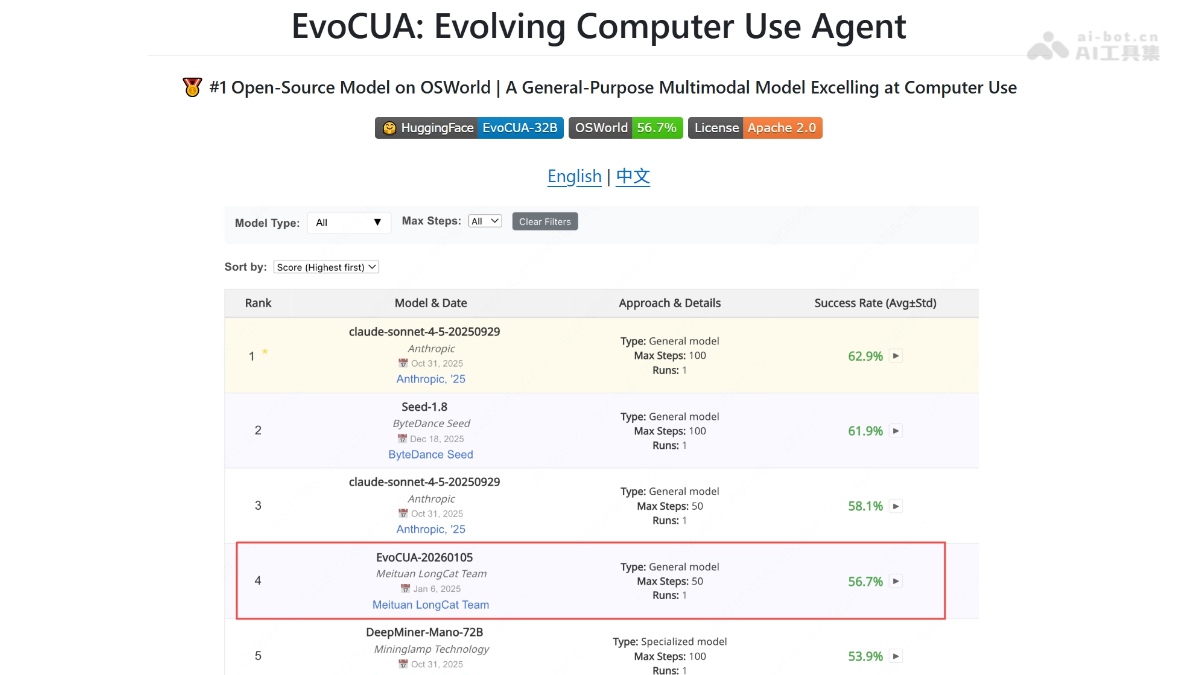
EvoCUA-美团开源
EvoCUA(Evolvin

VoiceSculpt
VoiceSculptor

ChatDev 2.0
ChatDev 2.0 是清

Qwen3-VL-Em
Qwen3-VL-Embed

Qwen3-VL-Re
Qwen3-VL-Reran
OS-Copilot-
OS-Copilot是开源的

Genie Sim 3
Genie Sim 3.0
HY-Motion 1
HY-Motion 1.0(

RedInk-开源免费
RedInk(红墨)是开源的
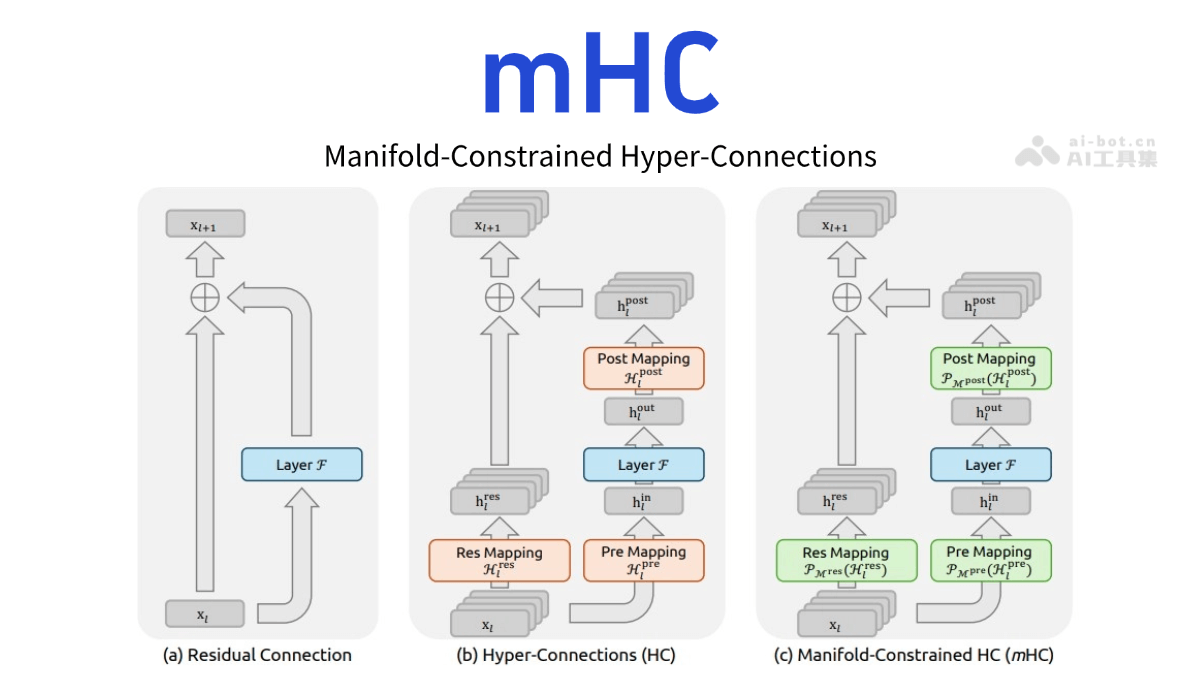
mHC-DeepSee
mHC(Manifold-C

IQuest-Code
IQuest-Coder-V

Vibe Kanban
Vibe Kanban 是开
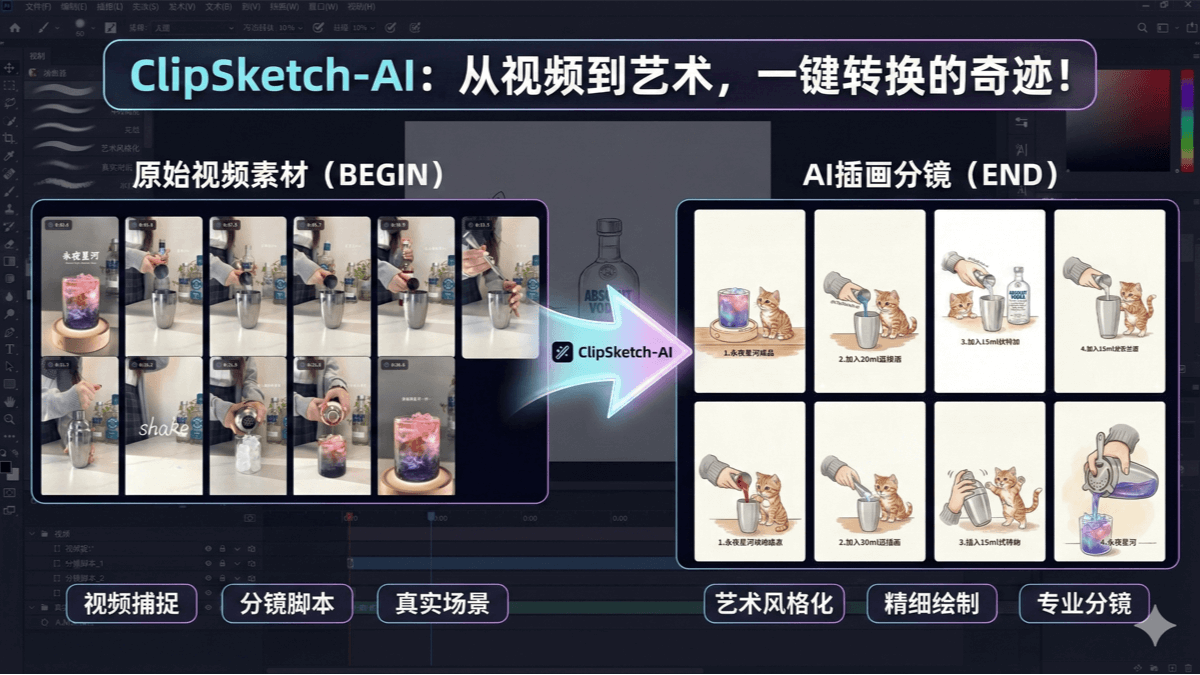
ClipSketch
ClipSketch AI

XVERSE-Ent-
XVERSE-Ent是元象科
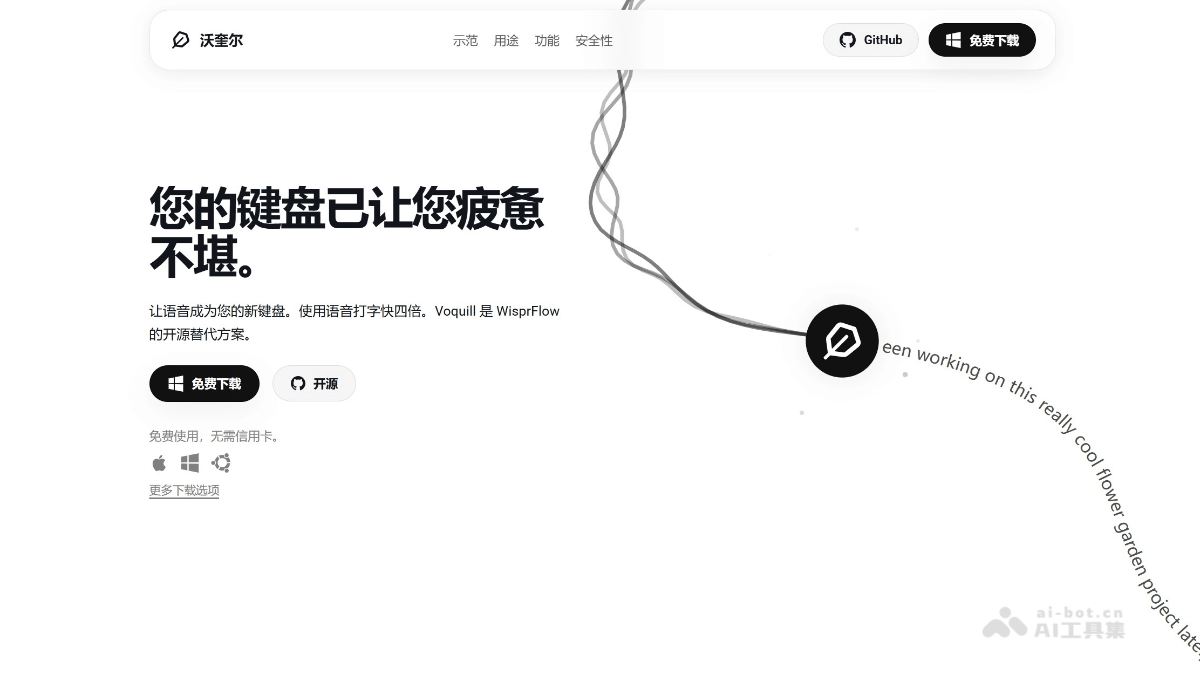
Voquill-开源A
Voquill是开源的语音输
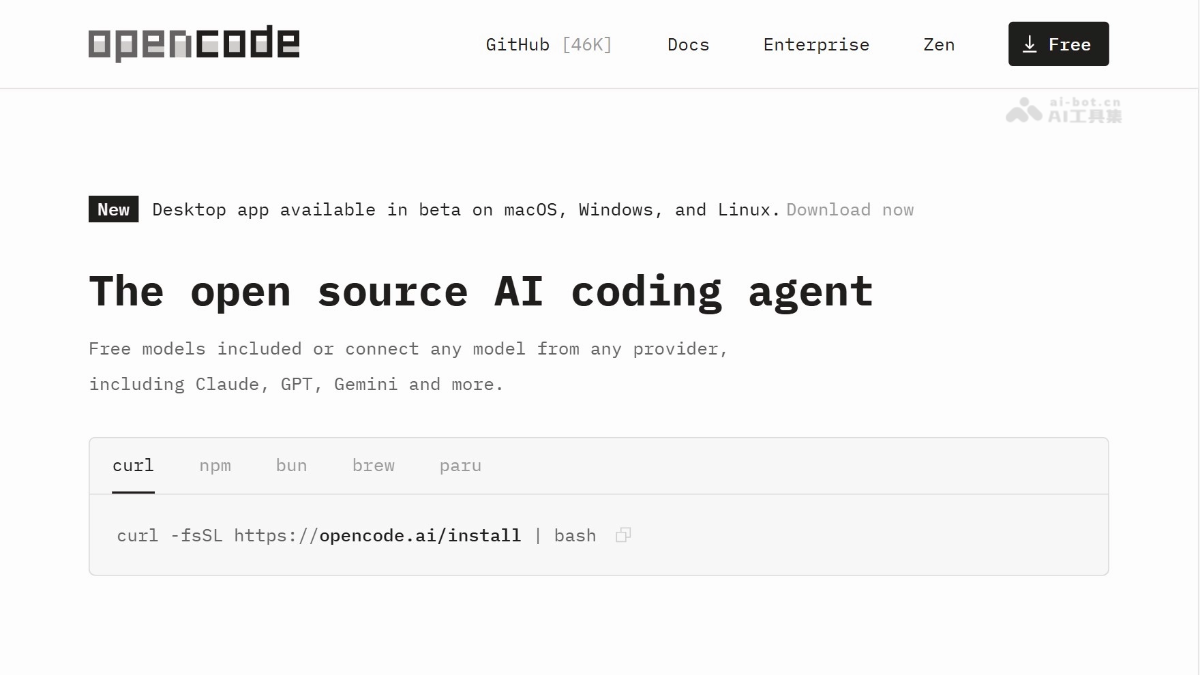
OpenCode-开源
OpenCode 是开源的
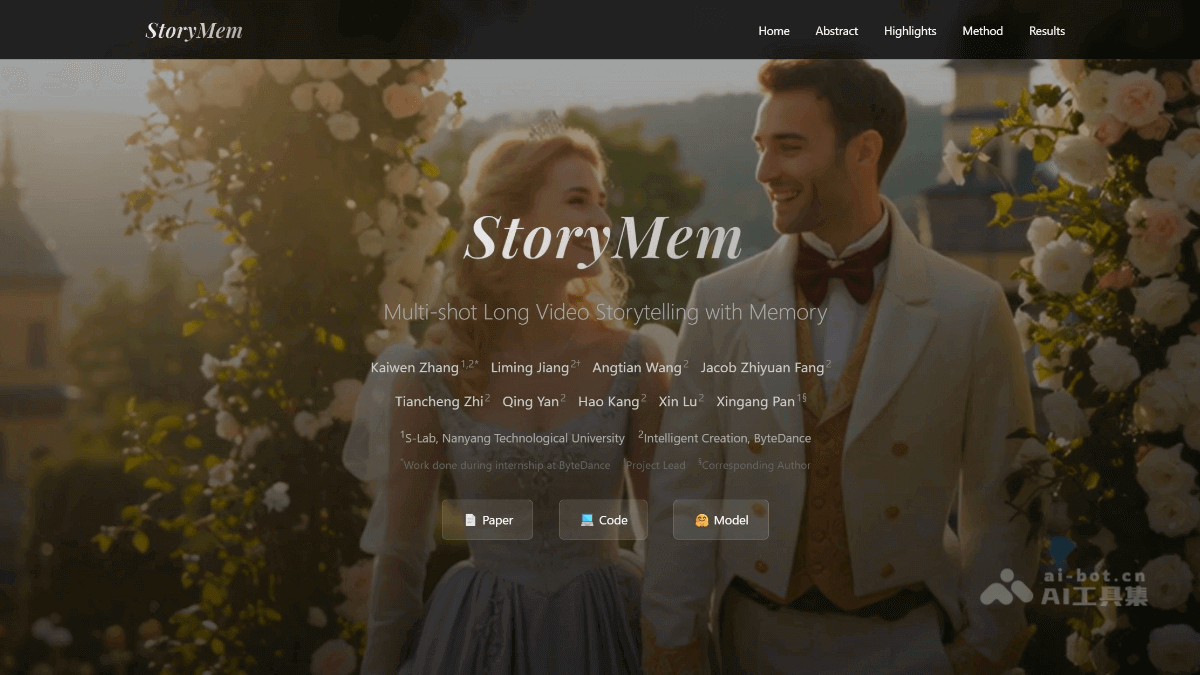
StoryMem-字节
StoryMem 是字节跳动

TuriX-CUA-开
TuriX-CUA 是基于

DLCM-字节跳动推出
DLCM(Dynamic L
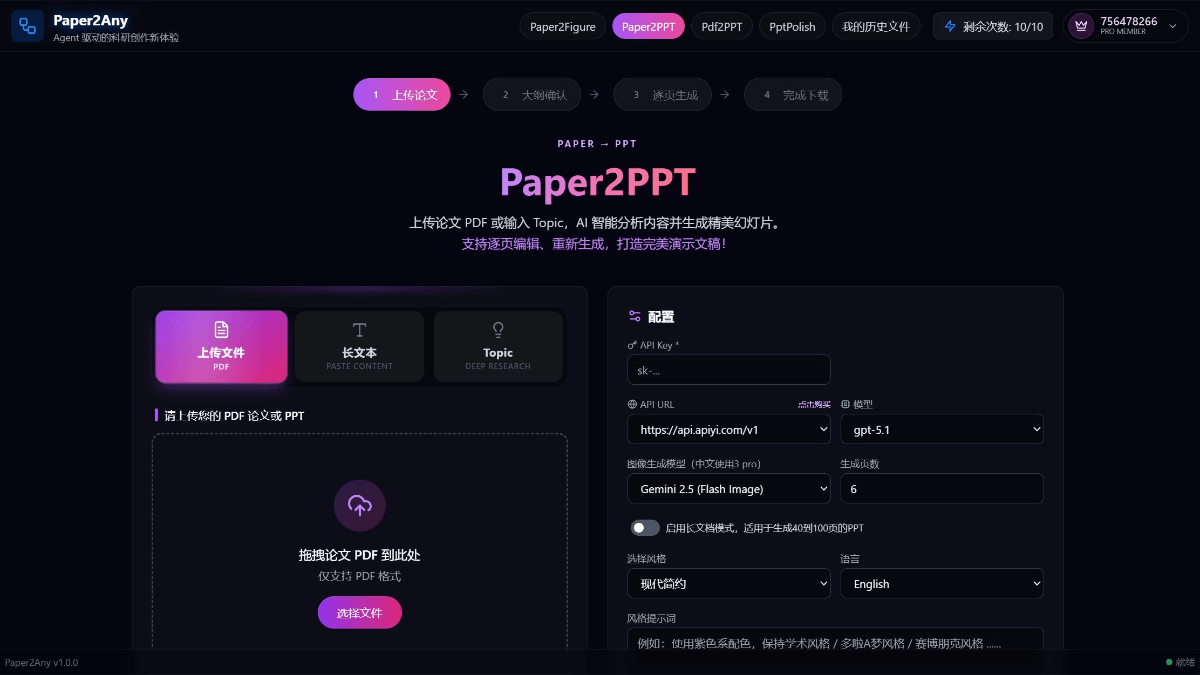
Paper2Any-北
Paper2Any是北京大学

openPangu-V
openPangu-VL-7

MiroThinker
MiroThinker v1

TeleChat3-中
TeleChat3是中国电信
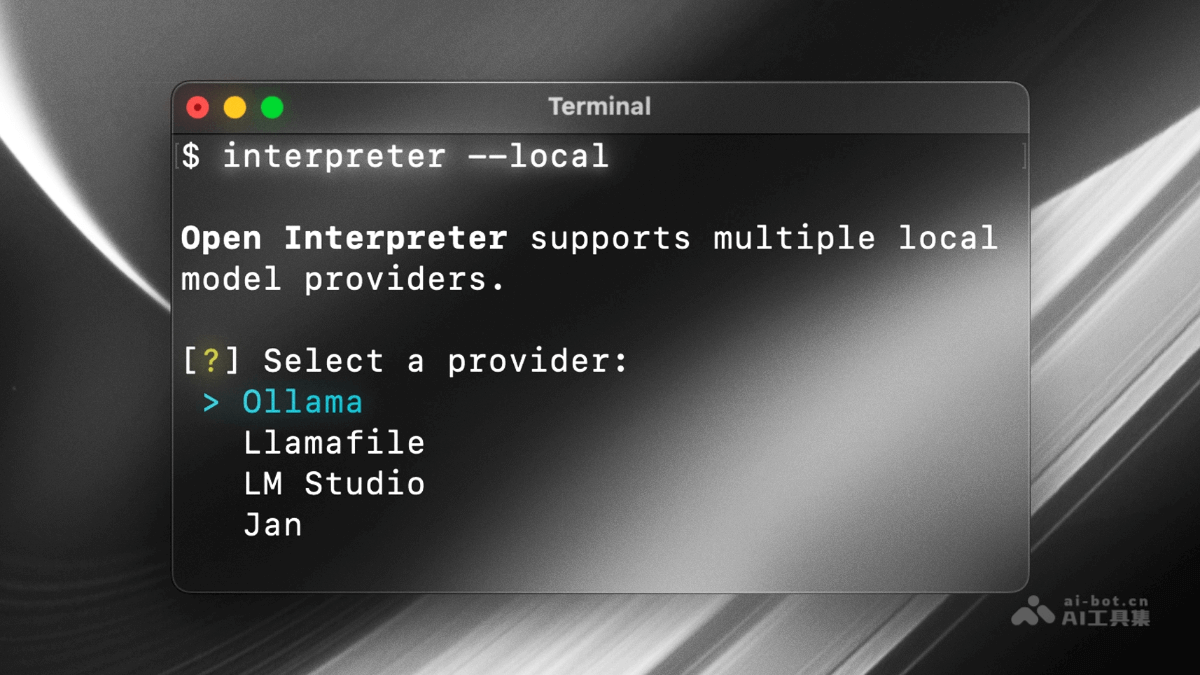
Open Interp
Open Interpret

10Kh RealOm
10Kh RealOmni-
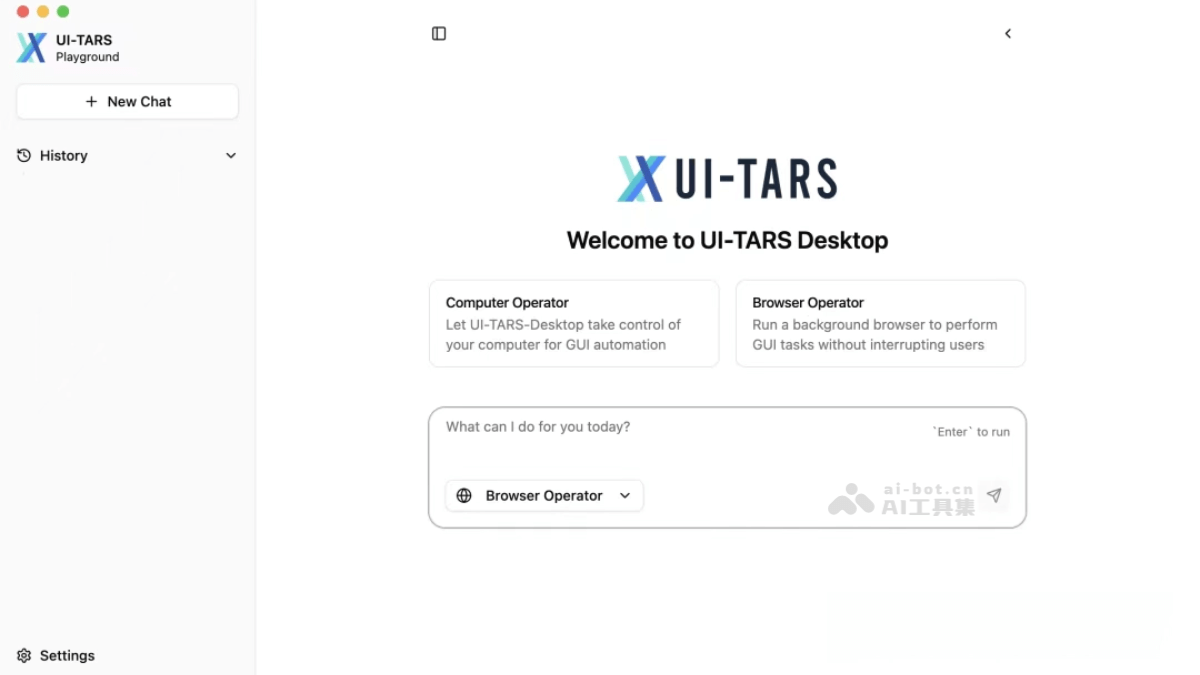
UI-TARS Des
UI-TARS Deskto
GLM-4.7-智谱推
GLM-4.7 是智谱AI推

MiniMax M2.
MiniMax M2.1 是