PaddleOCR 3.1震撼发布:三大升级助力AI开发,多语种、复杂文档、MCP服务器成亮点
文章来源:智汇AI 发布时间:2025-07-08
7月7日,百度AI团队重磅推出PaddleOCR 3.1版本,在多语种识别、复杂文档翻译、大模型连接能力上实现三大突破。新版本支持37种语言识别,精度大幅提升,还推出文档翻译产线与MCP服务器功能,…
暂无访问7月7日,百度AI团队正式宣布推出PaddleOCR3.1版本,这一更新在多语种识别、复杂文档翻译以及大模型连接能力上实现了三大突破。新版本不仅支持37种语言的文本识别,平均精度提升超30%,还推出了文档翻译产线和MCP服务器功能,为开发者提供了更高效、更便捷的AI应用开发工具。
PaddleOCR是什么?
PaddleOCR是基于百度飞桨(PaddlePaddle)深度学习框架开发的开源OCR工具库,旨在为开发者提供便捷、高效的文字识别解决方案。
PaddleOCR3.1推出三种新功能多语种识别:覆盖37种语言,精度提升超30%
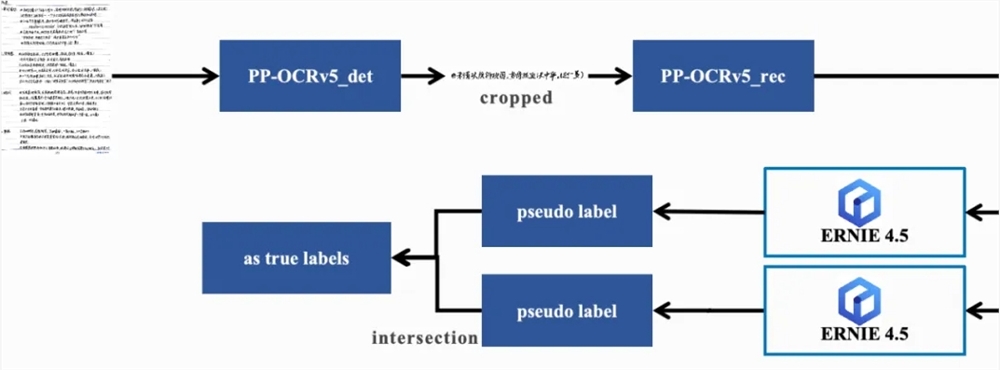
在全球化场景下,多语言识别一直是OCR技术的难点。PaddleOCR3.1新增了PP-OCRv5多语种模型,覆盖了法语、西班牙语、俄语等37种语言,解决了多语种数据稀缺的问题。通过融合文心4.5多模态大模型的视觉与文本理解能力,新模型能够自动完成高置信度的文本检测与数据标注,大幅提升了识别精度。
实测数据显示,在拉丁语系及东斯拉夫语言场景中,新模型的识别准确率提升超30%。例如,韩文识别错误率从8.7%降至2.1%,俄文复杂排版文档的解析速度提升2倍。这一改进使得PaddleOCR在国际化应用中更具竞争力,无论是跨境电商、跨国企业还是国际旅游,都能从中受益。
复杂文档翻译:PP-DocTranslation产线,专业领域翻译更精准
除了多语种识别,PaddleOCR3.1还推出了PP-DocTranslation翻译产线,结合PP-StructureV3文档解析引擎与文心大模型,实现了对PDF、图片中表格、公式、手写文字等复杂元素的智能识别与翻译。该工具能够将文档转换为Markdown格式后进行多语言翻译,支持用户上传术语对照表,实现“关键词汇”的精细化翻译。
这一功能在法律、医疗等专业领域尤为重要。例如,某跨国药企使用PP-DocTranslation后,药品说明书翻译效率提升40%,专业术语一致性达99.2%。这不仅节省了大量人力成本,还避免了因翻译错误导致的潜在风险。
MCP服务器功能:降低开发门槛,OCR能力无缝接入
为了进一步降低AI应用的开发门槛,PaddleOCR3.1推出了MCP(ModelContextProtocol)服务器功能。这一功能支持通过标准化协议将OCR能力无缝接入下游应用,开发者仅需几步即可搭建MCP服务,并通过本地Python库、飞桨星河社区或自托管服务调用核心功能,包括图像文字识别、文档版面分析等。
MCP的推出,意味着开发者无需从零开始开发OCR功能,只需通过简单的接口调用,即可快速构建出功能强大的AI应用。这不仅提高了开发效率,还降低了技术门槛,让更多企业和开发者能够轻松上手AI开发。
总结:PaddleOCR3.1,让AI开发更简单、更高效
PaddleOCR3.1的发布,无疑为OCR技术领域注入了新的活力。无论是多语种识别、复杂文档翻译还是MCP服务器功能,都展现了百度AI团队在技术创新上的实力与决心。对于开发者而言,PaddleOCR3.1不仅提供了更强大的工具,还降低了开发门槛,让AI应用开发变得更加简单、高效。
如果你正在寻找一款功能强大、易于上手的OCR工具,那么PaddleOCR3.1绝对值得一试。无论是国际化业务、专业领域翻译还是快速构建AI应用,它都能为你提供有力的支持。
github地址:https://github.com/PaddlePaddle/PaddleOCR
相关推荐
































