ActAnywhere-Adobe推出的AI视频背景生成模型
文章来源:智汇AI 发布时间:2025-08-07
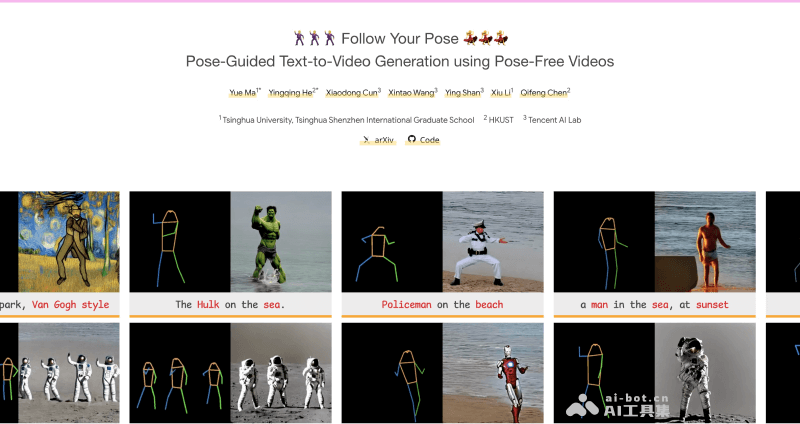
ActAnywhere是一个由斯坦福大学和Adobe Research的研究人员共同开发的视频生成模型,旨在解决视频背景生成的问题,特别是在需要将前景主体(如人
暂无访问ActAnywhere是什么
ActAnywhere是一个由斯坦福大学和Adobe Research的研究人员共同开发的视频生成模型,旨在解决视频背景生成的问题,特别是在需要将前景主体(如人物)与新背景无缝结合的场景中。这个模型适用于电影制作和视觉效果(VFX)领域,它能够自动化地创建与前景主体运动相协调的视频背景,从而节省了传统手动合成过程中的大量时间和精力。
官方项目主页:https://actanywhere.github.io/
Arxiv论文地址:https://arxiv.org/abs/2401.10822
ActAnywhere的功能特色
前景主体与背景融合:ActAnywhere能够根据前景主体的运动和外观,自动生成与之相匹配的背景,使得主体与背景之间的交互看起来自然和连贯。条件帧驱动的背景生成:用户可以提供一个描述新场景的图像(条件帧),ActAnywhere会根据这个条件帧生成视频背景。这允许用户指定特定的背景元素,如特定的建筑、自然景观或室内环境。时间一致性:通过使用时间自注意力机制,ActAnywhere确保生成的视频在时间序列上保持一致性,包括相机运动、光照变化和阴影效果。自监督学习:ActAnywhere在大规模人类-场景交互视频数据集上进行自监督训练,这意味着它能够在没有人工标注的情况下学习如何生成视频背景。零样本学习:ActAnywhere能够在没有额外训练的情况下,对新的、未见过的数据(如非人类主体)进行生成,这表明模型能够从训练数据中学习到通用的背景生成策略。ActAnywhere的工作原理
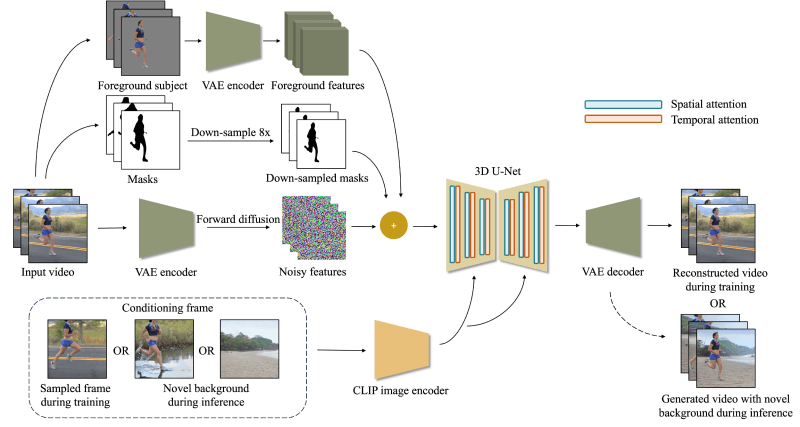
ActAnywhere通过以下的步骤和组件,能够生成具有高度现实感和时间连贯性的视频背景:
数据准备:使用前景主体分割算法(如Mask R-CNN)从输入视频中获取前景主体的分割序列(S)和对应的掩膜(M)。引入一个条件帧(c),这是一个描述所需生成背景的图像,可以是背景图像或包含前景和背景的复合帧。特征编码:使用预训练的变分自编码器(VAE)将前景主体分割序列编码为潜在特征(ˆS)。将前景掩膜序列下采样并与潜在特征对齐,以匹配特征维度。扩散过程:在训练过程中,使用VAE编码器将原始视频帧编码为潜在表示(Z),然后在正向扩散过程中逐渐添加高斯噪声。在测试时,潜在表示(Z0)初始化为高斯噪声,并通过逆向扩散过程逐步去噪,以生成最终的视频帧。时间注意力机制:在去噪的U-Net中插入一系列运动模块,这些模块包含特征投影层和1D时间自注意力块,以实现时间上的连贯性。条件帧的特征(Fc)通过CLIP图像编码器提取,并注入到U-Net的交叉注意力层中,以确保生成的视频背景与条件帧保持一致。训练目标:使用简化的扩散目标进行训练,即预测添加的噪声。通过最小化预测噪声与真实噪声之间的差异来训练模型。数据增强和处理:在训练过程中,为了处理不完美的分割掩膜,应用随机矩形裁剪和图像腐蚀操作。在测试时,通过随机丢弃分割、掩膜或条件帧来实现无分类器的引导。模型训练:在大规模人类-场景交互视频数据集(HiC+)上进行训练,该数据集包含240万个视频。使用AdamW优化器,固定学习率为3e-5,冻结共享的VAE和CLIP编码器,微调U-Net。生成过程:在测试时,将前景主体序列和条件帧输入到训练好的模型中,模型将生成与前景主体运动相协调的视频背景。ActAnywhere的应用场景
视频背景替换:ActAnywhere可以将视频中的前景主体放置到全新的背景中,这对于电影制作、广告、虚拟现实(VR)和增强现实(AR)等领域非常有用。例如,可以将演员置于虚构的场景中,或者在不实际拍摄的情况下模拟特定环境。视觉效果增强:在视觉效果(VFX)制作中,ActAnywhere可以用来生成复杂的背景效果,如动态天气、光影变化、人群互动等,而无需实际拍摄这些元素。创意内容制作:艺术家和内容创作者可以使用ActAnywhere来快速尝试和实现他们的创意想法,例如,将角色置于不同的历史时期或未来世界,或者与虚构的生物互动。教育和培训:在教育领域,ActAnywhere可以用来创建模拟场景,帮助学生更好地理解复杂的概念或历史事件,或者用于安全培训,模拟紧急情况。游戏和娱乐:游戏开发者可以利用ActAnywhere生成动态背景,为玩家提供更加丰富和真实的游戏体验。同时,它也可以用于电影预告片、音乐视频和其他娱乐内容的制作。相关推荐