Step R-mini – 阶跃星辰推出的 Step 系列首个推理模型
Step R-mini是什么
Step R-mini(全称Step Reasoner mini)是阶跃星辰推出的推理模型, 是 Step 系列模型家族的首个推理模型,擅长主动规划、尝试和反思,基于慢思考和反复验证的逻辑机制,为用户提供准确可靠的回复。模型既擅长解决逻辑推理、代码和数学等复杂问题,也能兼顾文学创作等通用领域。Step R-mini在数学基准测试和代码任务上表现优异,实现了文理兼修。Step R-mini坚持 Scaling Law 原则,包括强化学习、数据质量、测试时计算和模型规模的扩展。
Step R-mini的主要功能
数学问题:构建合理的推理链,对复杂数学问题进行规划和逐步求解。在解答奥数难题时,枚举不同解法方案进行交叉验证。处理几何题目时,主动用画草图构建深度思考的内容介质,全面严谨地分析题目需求,选择最佳解题公式,基于多次自我追问确定是否有没被考虑到的因素。逻辑推理:自主尝试多种解题思路,在得到初步答案后,自我反问尝试有没有其他可能性,确保枚举出所有效果良好的解决方案,在交卷前检查有无遗漏,提供全面且准确的推理结果。代码解答:基于长推理链正确解答难度较高的算法题,如 LeetCode 技术平台上评级为“Hard”的题目。还能处理复杂的开发需求,逐步分析用户需求和意图,构建代码逻辑,在代码写作中穿插对当前代码片段的分析和验证,最终给出可执行的代码。文学创作:深入理解用户的表达需求,分析创作主题、文学题材要求,思考创作角度、描绘的景物、修辞手法、内容结构等,赋予事物人类情感层面的象征意义,并增加个性化、创新的表达风格,像个“追求完美”的创作者。Step R-mini的技术优势
坚持 Scaling Law 原则:Scaling Reinforcement Learning:从模仿学习到强化学习,从人类偏好到环境反馈,用强化学习为模型迭代的核心训练阶段。Scaling Data Quality:在确保数据质量的前提下,持续扩大数据分布与规模,为强化学习训练提供保障。Scaling Test-Time Compute:兼顾测试阶段的计算扩展,System 2 的范式让 Step-Reasoner mini 能在极复杂任务推理上,达到 50,000 tokens 进行深度思考。Scaling Model Size:坚持模型规模扩展是 System-2 的核心,正在开发更智能、更通用、综合能力更强的 Step Reasoner 推理模型。文理兼修:在 AIME 和 Math 等数学基准测试上,成绩超过 o1-preview,比肩 OpenAI o1-mini。在 LiveCodeBench 代码任务上,效果优于 o1-preview。大部分推理模型难以兼顾文理科双方向能力, Step R-mini 基于大规模的强化学习训练,用 On-Policy(同策略)强化学习算法,实现“文理兼修”。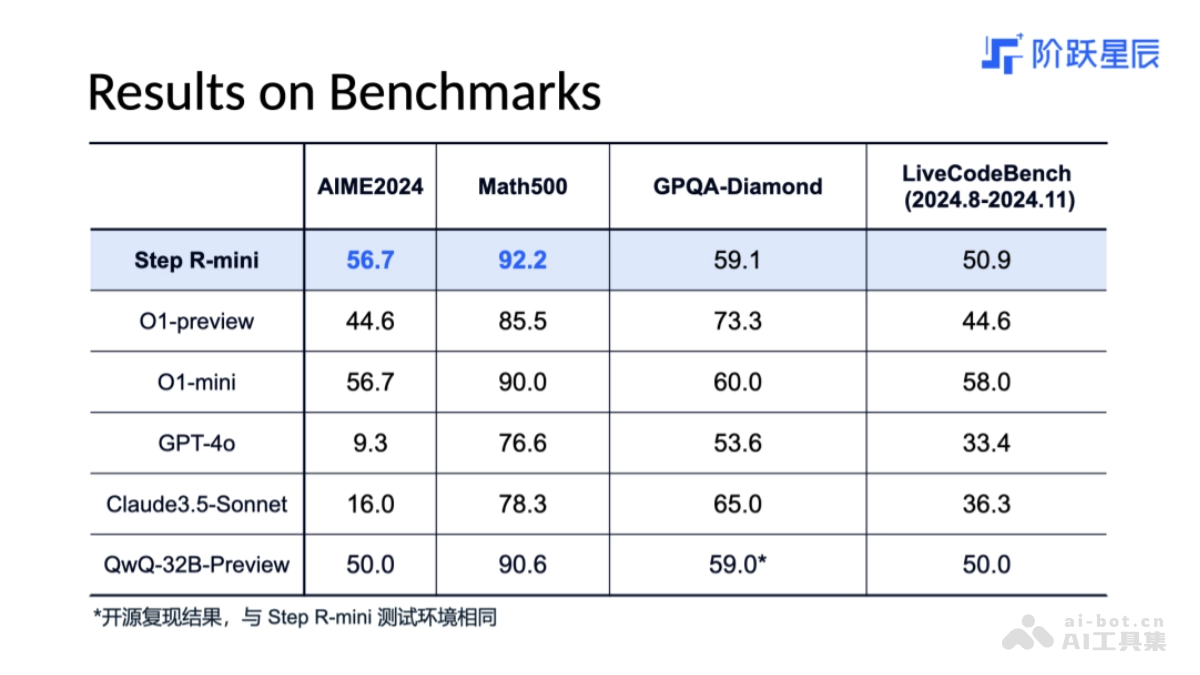
Step R-mini的项目地址
项目官网:Step R-miniStep R-mini的实例展示
逻辑推理:在处理逻辑推理任务时,Step R-mini自主进行多种解题思路的尝试,在得到初步答案后,自我反问尝试有没有其他可能性,确保枚举出所有效果良好的解决方案,并在交卷前检查有无遗漏。








