“大模型”争相涌现,国产AI开启大乱斗,测评国内各种对标ChatGPT的大语言模型
AI奇点网5月4日报道丨转载自 知乎 JioNLP团队
最近一段时间,几乎所有国内互联网大中公司都在宣称即将推出、早已深造、启动专项自家的对标 ChatGPT 的大模型。

继百度文心一言发布之后,目前已经推出公测接口的有阿里的通义千问,讯飞的星火大模型,ChatGLM,复旦的 Moss。而其他家都还处于开发或内测阶段,并未开放对外公测。目前各家的效果依然是王婆卖瓜,自说自话,缺乏统一标准。
为了把所有的公测大模型都拉齐到同一个水平线上进行横向比较,我制作了一份 JioNLP-大语言模型评测数据集,用于考察各个大语言模型的实际效果。
LLM 评测数据集简介
jionlp 提供了一份 LLM 评测试题数据集,主要用于评测通用 LLM 的效果评价。
着眼点:考察 LLM 模型对人类用户的帮助效果、辅助能力,可否达到一个方便、可靠的【智能助手】的水平。
题型介绍:选择题来源于中国大陆国内各种专业性考试,日常生活常识,重点在于考察模型对客观知识的覆盖面,占比 52%;主观题主要考察用户对 LLM 常用功能的效果。详细情况如下:
题型分值形式内容来源知识问答32选择题覆盖各领域知识题,考察模型预训练语料的丰富性、准确性国内专业性考试生活常识10选择题覆盖衣食住行的生活常识,考察模型是否经常犯低级错误日常生活总结逻辑推理5选择题考察模型的语言理解能力国内通用考试语言表达5选择题考察模型的逻辑推理、分析能力国内通用考试文本问答40选择题考察模型完成各种用户指令的能力常用若干能力机器翻译8选择题考察模型的语言能力,翻译能力论文和新闻评分规则:
客观选择题每题一分主观题每道5分,5分满分要求模型反馈答案正确,可使用,不需要或极少需要用户做人工调整和修改。0分,答非所问,语言不通。翻译题每道4分,4分,要求翻译精准,特定词汇准确。0分,无法阅读,词不达意。样例


说明
客观题
用户:请回答问题:xxxxxxxx,A,xxx;B,xxx;C,xxx;D,xxx
模型:答案选A,原因是xxxxxx。
覆盖数学、物理、化学、生物、计算机、通信、机械、电力、医学、法律、新闻、地理、历史、文学、经济、编程等方面常识性问题;难易程度不一,存在少量多选题;若模型给出答案字母(ABCD),但分析结果错误,仍然判定正确;若模型未给出答案字母,但以文字形式给出正确结果,仍然判定正确;个别选择题没有正确答案,或题干信息给的不完全,无从给出答案;此时要求模型能够正确辨别题目中的问题,不能给出任何选项答案。此做法考察模型的信息辨别能力,避免幻觉妄语 Hallucination 的能力。客观题由于模型的输出以概率形式进行采样,具有不确定性。评测过程中,全程都仅做一次输出,不会反复测试以期模型输出正确结果为止。主观题
主要覆盖写文章、写代码、写脚本、讲故事、完成用户知识咨询、特定主观问题咨询、考察模型输出陷入死循环,传统 NLP 任务等能力。加载数据集
jionlp 工具包提供了评测试题数据集,python 语言,使用方式如下:
$ pip install jionlp
>>> import jionlp as jio
>>> llm_test = jio.llm_test_dataset_loader()
>>> print(llm_test[15])
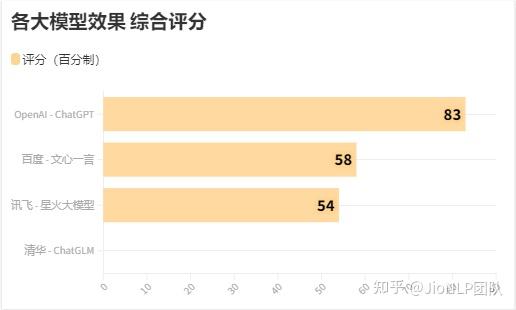
测试结果
规划和请求
有一些模型需要提供邀请码才可测试,欢迎大家提供邀请码,或直接使用测试题进行测试。
该测试集将持续跟踪国内其它厂商的大模型效果评测。