PageIndex:一个开源PDF文档索引系统,可实现更精准、更逻辑化的检索
文章来源:智汇AI 发布时间:2025-05-01
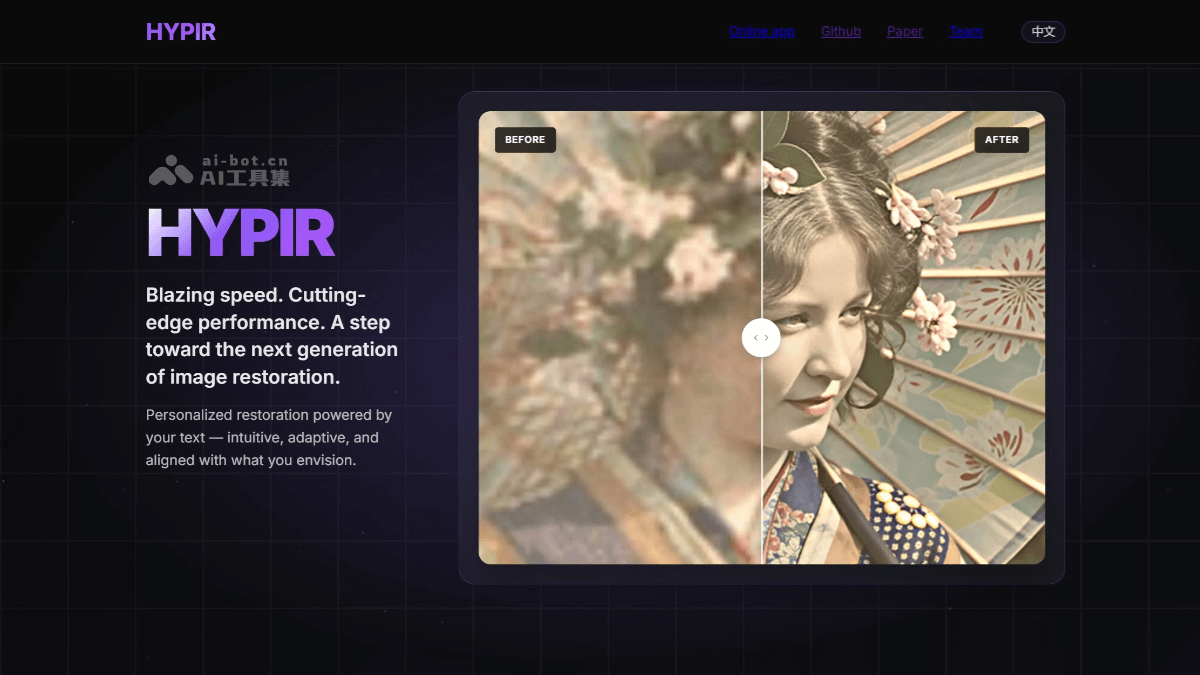
PageIndex是一个开源的文档索引系统,能提升长篇专业文档的检索准确性和LLM的推理能力。它通过将PDF文档转化为层次化的树状结构,取代了传统的向量RAG语义相似度搜索,从而实现更精准、更逻辑化的检索。
暂无访问PageIndex是什么?
PageIndex 是一个开源的PDF文档索引系统,只要提升长篇专业文档的检索准确性和LLM的推理能力。它通过将PDF文档转化为层次化的树状结构,取代了传统的向量 RAG 语义相似度搜索,从而实现更精准、更逻辑化的检索。
PageIndex核心功能包括将文档转化为类似智能目录的树状结构,提供精准的页面定位,避免随意分块,并适配超长文档,轻松处理数百甚至上千页的内容。
工作原理是将 PDF 文档转化为语义树结构,结合查询分析、文档选择、节点选择和内容生成,最终提供准确的回答。与依赖向量数据库或传统分块方式的系统不同,PageIndex 完全免费且开源。它特别适合处理金融报告、监管文件、学术教科书、法律或技术手册,以及任何超出LLM上下文限制的文档。
PageIndex核心功能
文档处理:能够处理长文档,尤其是专业文档,通过构建搜索树结构来为基于推理的检索增强生成(RAG)做好准备。
目录提取与处理
可以从文档中提取目录内容,处理目录中有无页码的不同情况。
对目录进行转换,将其转换为特定的 JSON 格式,方便后续处理。
页码处理:为目录项添加物理索引,处理页码缺失或不正确的情况,通过多次尝试修复不正确的目录项。
节点处理:对大节点进行递归处理,将其拆分为更小的节点,以满足 token 数量和页面数量的限制。
验证修复:验证目录的准确性,计算准确率,并对不准确的结果进行修复。
PageIndex特点
层次树结构:使 LLM 能够逻辑性地遍历文档,就像一个智能的、为 LLM 优化的目录。
精确页面引用:每个节点包含其摘要和开始/结束页面的物理索引,实现精准检索。
无任意分块:不使用任意分块,节点遵循文档的自然结构。
支持大规模文档:设计用于轻松处理数百甚至上千页的文档。
PageIndex适用场景
金融领域
财务报告分析:快速定位关键财务数据和指标。
监管文件解读:精准查找法规条款,确保合规。
法律领域
法律文件检索:高效查找法律条款和案例。
合同审查:快速定位合同中的关键条款。
学术研究
学术论文检索:快速找到研究结果和理论支持。
教科书学习:便捷定位特定章节和知识点。
技术文档
技术手册:快速查找操作步骤和技术参数。
项目文档:高效检索项目中的关键信息。
企业内部
内部报告:快速定位长篇报告中的关键内容。
知识库管理:提升知识共享和检索效率。
医疗领域
医学文献检索:快速找到研究结果和治疗方法。
临床指南:精准定位临床操作指南。
教育领域
在线课程资料:快速查找课程重点内容。
考试复习资料:高效定位复习要点。
政府机构
政策文件解读:快速查找政策条款。
公共信息检索:提升公共服务效率。
PageIndex使用方法
1. 安装依赖项
pip3install-rrequirements.txt2. 设置 Openai API 密钥
在根目录创建一个 .env 文件并添加你的 API 密钥:
CHATGPT_API_KEY=your_openai_key_here3. 对 PDF 运行 PageIndex
python3run_pageindex.py--pdf_path/path/to/your/document.pdf还可以通过额外的可选参数自定义处理过程,例如:
--modelOpenAImodeltouse(default:gpt-4o-2024-11-20)--toc-check-pagesPagestocheckfortableofcontents(default:20)--max-pages-per-nodeMaxpagespernode(default:10)--max-tokens-per-nodeMaxtokenspernode(default:20000)--if-add-node-idAddnodeID(yes/no,default:yes)--if-add-node-summaryAddnodesummary(yes/no,default:no)--if-add-doc-descriptionAdddocdescription(yes/no,default:yes)Github:https://github.com/VectifyAI/PageIndex
项目官网:https://vectify.ai/pageindex
相关推荐