可灵AI运用什么技术
- 自研大模型技术:
- 可灵AI基于快手自研的可灵和可图大模型,这些大模型经过大量的数据训练和优化,能够生成高质量的视频和图像内容。
- 3D时空联合注意力机制:
- 该技术能够对运动物体和场景进行精确建模,从而生成符合真实物理规律的动态画面。这种技术能够捕捉大规模运动的复杂细节,使生成的视频更加真实和流畅。
- Diffusion Transformer架构:
- 这种架构能够通过对文本和视频语义的深刻理解,将用户的想象具象化为逼真的视觉画面。它使得可灵AI能够根据用户的输入(如文本描述或图像提示)生成高质量的动态视频内容。
- 多模态AI技术:
- 可灵AI结合了自然语言处理和图像生成的强大能力,支持多种输入方式(如文本、图像等)和输出方式(如视频、图像等)。这种多模态技术为用户提供了更丰富的创作体验和更广泛的应用场景。
- 深度学习技术:
- 可灵AI在生成视频和图像时,运用了深度学习技术中的生成对抗网络(GAN)和卷积神经网络(CNN)等模型。这些模型通过对大量数据的学习和优化,能够生成更加逼真和高质量的内容。
- 先进的视频生成技术:
- 除了上述技术外,可灵AI还采用了先进的视频生成技术,如视频续写、对口型功能等。这些技术使得用户可以在已有的视频基础上进行创作和编辑,进一步丰富了视频内容的多样性和个性化。
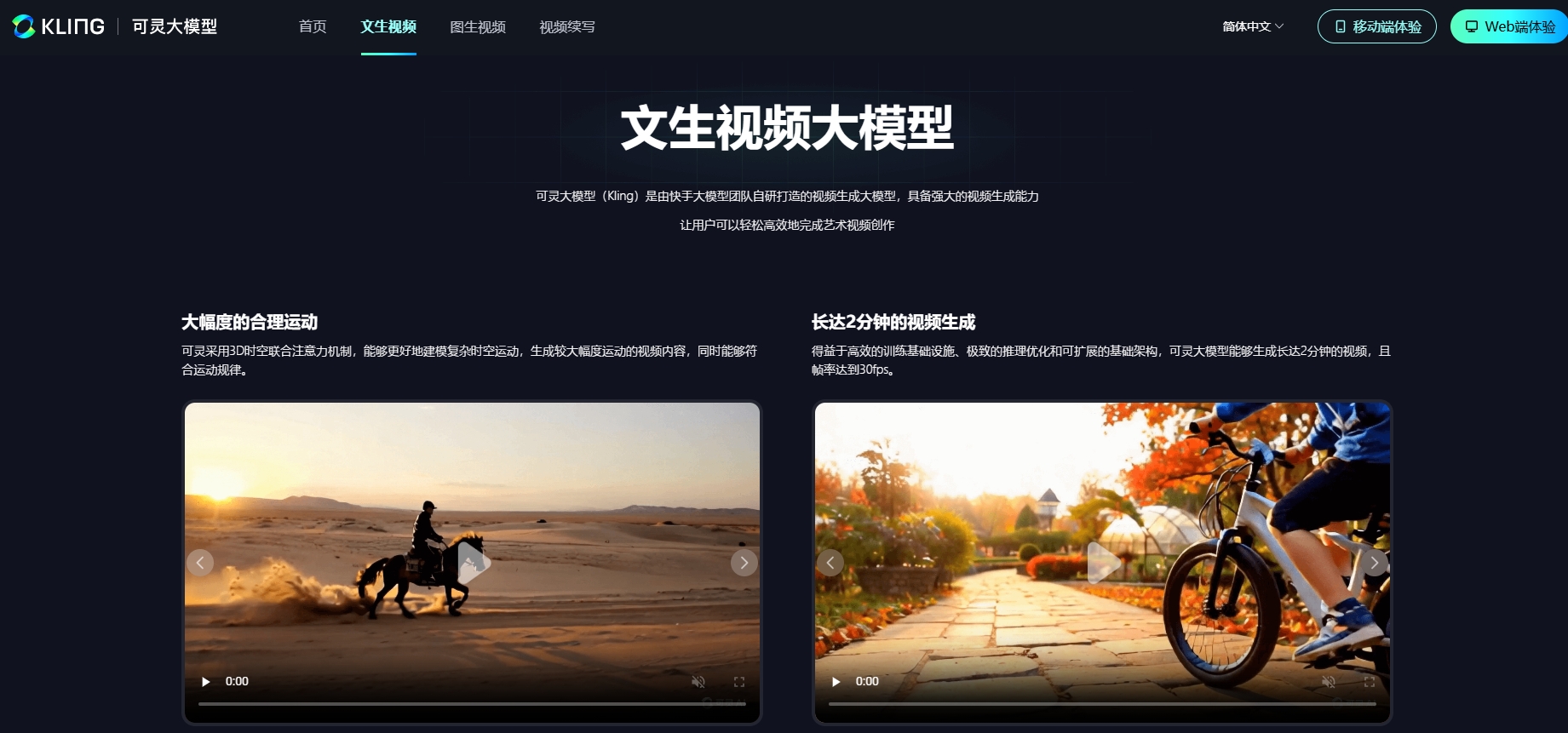
综上所述,可灵AI运用了自研大模型技术、3D时空联合注意力机制、Diffusion Transformer架构、多模态AI技术、深度学习技术以及先进的视频生成技术等多种先进技术。这些技术的结合使得可灵AI在视频生成领域具有强大的能力和广泛的应用前景。